指针是 C 语言公认的难点,要不然也不会有那么多 C 语言的书籍专门将“指针”放在标题中进行强调了:
- 《C 和指针(Pointers on C)》
- 《征服 C 指针》
- 《深入理解 C 指针(Understanding and using C pointers)》
- Pointers in C: A Hands on Approach
- …
同时,指针也是 C 语言最重要的特性,你不可能在不掌握指针的情况下用好 C。本文试图带你彻底攻克这个难点,让你可以像 Neo 看透 Matrix 一样,看破“指针”。

本文的主要内容来自《征服 C 指针》和《C 专家编程》,这不是两本通常意义的 C 语言入门书,没有罗列式的讲解 C 的语法,而是能将知识点融会贯通,带有作者鲜明的个人风格,体现出他们丰富的实践经验。《C 专家编程》的作者 Peter van der Linden 曾在 Sun 和 Apple 工作,是 Sun 编译器、SunOS kernel 和 Solaris kernel 的核心开发成员。
# 什么是指针
指针概念本身并不难,稍有编程经验的人都很容易理解:和 int,double 等类型一样,指针也是一种类型,它的值是内存地址。我们用指针来保存其他类型变量的地址。
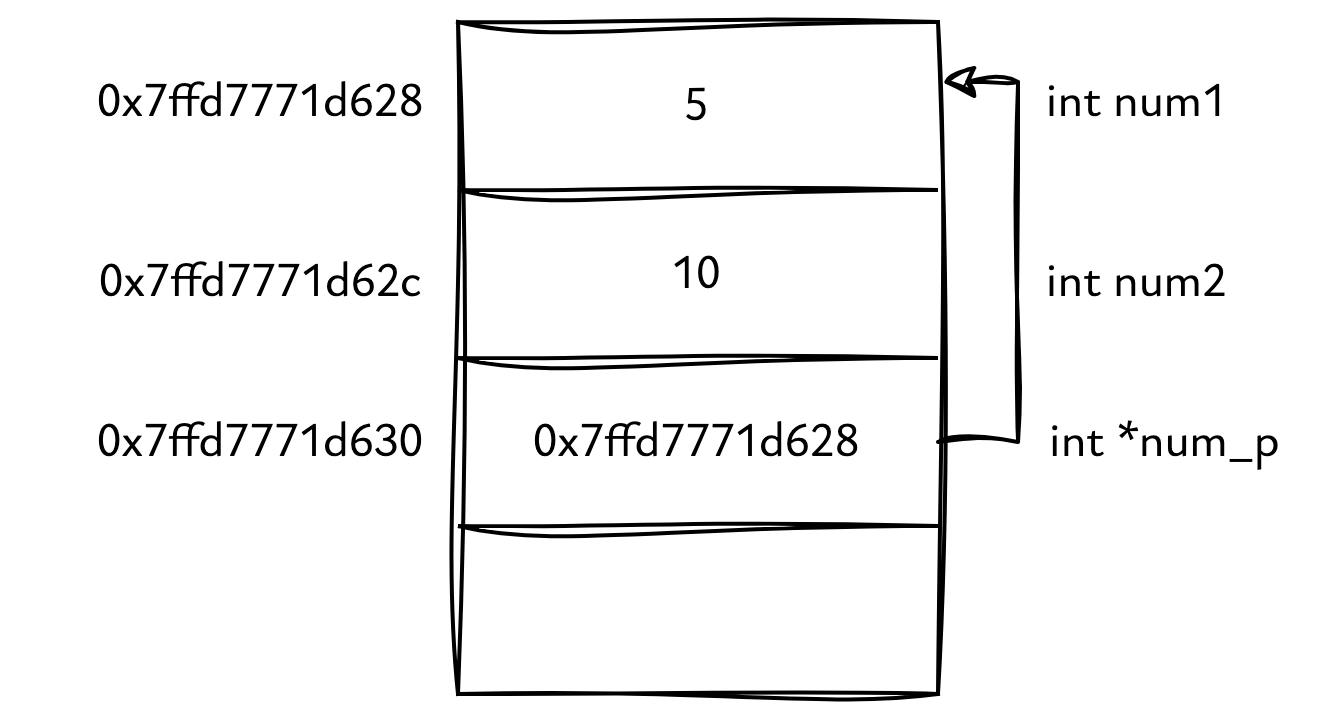
如上图,变量 num1 的类型是 int,它的值是 5;变量 num_p 的类型是指向 int 的指针类型,它的值是变量 num1 的内存地址。
指针变量 num_p 在初始化时不指向任何变量:
|
|
可以对 int 类型的变量 num1 使用取地址运算符 &,获取变量 num1 的地址,然后赋值给指针变量 num_p ,这时指针 num_p 中的值就是变量 num1 的地址:
|
|
对指针使用间接运算符 *,表示该指针指向的变量。可以通过指针 num_p 修改变量 num1 的值:
|
|
补充
变量名本质上是内存地址的别名,只是为了引用地址方便。在编译后生成的机器代码中,变量名被替换为相应的内存地址,变量名本身不会出现在最终的机器代码中。为了调试方便,编译器在生成可执行文件时可以选择保留符号信息(使用
-g选项)。调试符号信息包含了变量名、行号、文件名等信息。
# 为什么 C 的指针很难
了解了指针的基本概念,你会觉得:就这,一点也不难呀。实际上,C 语言指针的难点并不是指针概念本身,而是在于下面两个原因:
- 指针和 C 语言混乱的声明语法纠缠在一起
- 指针和数组的微妙关系
先看第一个原因,下面这个函数原型声明来自 telnet 程序:
|
|
初次看到这样的声明让人头大,这到底是什么指针呀!不能简单的用“指针就是地址”来理解这里的指针。
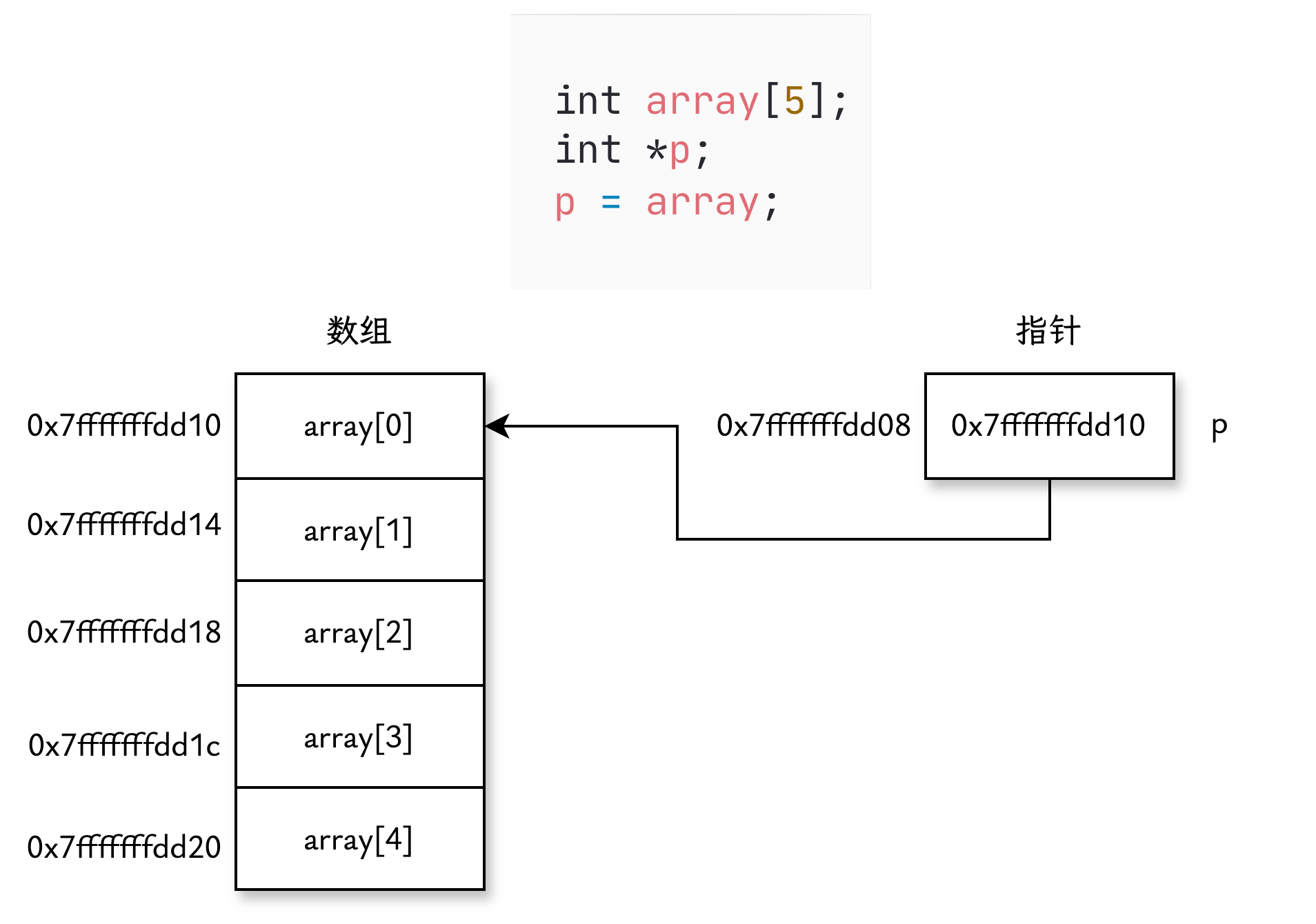
第二个原因,数组和指针在很多情况下可以“互换”使用。例如声明 int 数组和指针,并将数组赋值给指针:
|
|
我们可以使用指针运算的方式访问数组元素:
|
|
也可以把指针当做数组,使用下标访问数组元素:
|
|
甚至可以对数组变量进行指针运算:
|
|
给人的感觉是,数组和指针完全等价,可以互换使用,但这个说法并不完全正确。
数组和指针本来就是不同的东西,虽然在很多场景下它们可以互换使用,但有些场景却必须严格区分。对指针和数组的混乱认知,是造成指针难以理解的另一个重要原因。
因此,我们要攻克 C 语言的指针,只了解指针的基本概念是完全不够的,必须彻底搞懂 C 语言的声明,以及指针和数组的关系。下面我就分别进行介绍。
# 解读 C 语言的声明
# 混乱的声明语法
C 的声明语法有些奇怪,原因是 C 语言最初的设计哲学:对象的声明形式与它的使用形式尽可能相似。例如声明一个 int 类型的指针数组:
|
|
然后以 *p[i] 这样的形式使用指针所指向的 int 数据,声明和使用的形式非常相似。然而这并不是一个确定的规则,例如当我们在指针类型上使用下标运算符时:
|
|
对指针的声明和使用形式就完全不同。在引入 volatile 和 const 关键字后,就出现了更大的破绽:这些关键字只能出现在声明中,并不会出现在使用中,声明和使用完全相同的情况越来越少。看来当初决定让声明和使用形式上相同不是一个好主意。
回到前面 int 指针数组的声明 int *p[3],只从声明的表面上看,你不能确定 int *p[3] 是一个 int 类型的指针数组,还是一个指向 int 数组的指针。你必须记住操作符的优先级,下标操作符 [] 的优先级最高,才能确定 p 首先是一个数组,然后它的元素是 int 类型的指针。
这就是 C 语言声明最大的问题,无法以一种自然方式从左向右解读一个声明。遇到下面这样的声明,即使是经验丰富的 C 程序员也会觉得麻烦:
|
|
《C 专家编程》给出了一种方法,让解读复杂声明变得轻松。
# C 声明的优先级规则
我们可以按照下面表格分步拆解声明,将 C 的声明解读为自然语言。
| C 声明的优先级规则 | |
|---|---|
| A | 声明从名称开始,然后按照优先级顺序阅读。 |
| B | 优先级从高到低的顺序为: |
| B.1 | 声明中被括号括起来部分 |
| B.2 | 后缀运算符: |
括号 () 表示函数 |
|
方括号 [] 表示数组 |
|
| B.3 | 前缀运算符:星号表示“指向…的指针”。 |
| C | 如果 const 和/或 volatile 关键字紧邻类型说明符(例如 int、long 等),则它们作用于类型说明符。否则, const 和/或 volatile 关键字作用于其左边的指针星号。 |
现在用上面表格定义的优先级规则,来解读这个原型声明:
|
|
| 应用规则 | 解释 |
|---|---|
| A | 首先,找到变量名 “next”,并注意它直接被括号包围 |
| B.1 | 然后,我们将括号中的内容作为一个整体 |
| B.3 | 进入括号内,注意到前缀操作符 *,得出“next 是一个指针,它指向…” |
| B | 然后,我们走出括号,可以选择前缀操作符 * 或者后缀操作符 () |
| B.2 | 规则 B.2 告诉我们优先级较高的是右边的函数括号 (),因此我们得到“next 是指针,它指向一个函数,这个函数返回… ”。 |
| B.3 | 接着处理前缀星号 *,得出“这个函数返回一个指针,它指向…” |
| C | 最后,将 “char * const” 解释为“指向 char 的只读指针” |
将所有部分结合在一起可以解读为:
“next 是一个指针,它指向一个函数,这个函数返回一个指针,该指针指向另一个指针,它是一个指向 char 的只读指针。”
对照上面的优先级规则表格,我们很容易的将复杂的声明,转换为了易于理解的自然语言。
再试试另外一个例子:
|
|
按照声明的优先级规则解读:
| 应用规则 | 解释 |
|---|---|
| A | 从变量名 c 开始 |
| B | 可以选择前缀操作符 * ,或者后缀操作符 [] |
| B.2 | 选择优先级较高的右边方括号[],因此我们得到“c 是一个包含了 10 个元素数组,元素类型是…” |
| B.3 | 接着处理前缀星号 *,得出“元素类型是指针,它指向…” |
| B.1 | 将括号中的内容作为一个整体 |
| B | 可以选择前缀操作符 * 或者后缀操作符 () |
| B.2 | 选择优先级较高的右边函数括号 (),因此我们得到“**… 是一个函数,这个函数接收的参数是 int **p,返回值是… **”。 |
| B.3 | 接着处理前缀星号 *,得出“返回值是一个指向 char 的指针” |
最后将所有部分合在一起:
“c 是一个包含了 10 个元素数组,元素类型是指针,它指向是一个函数,这个函数接收的参数是 int **p,返回值是一个指向 char 的指针。”
完美!按照这个规则,再复杂的声明都能读懂了。
我们可以按照上面表格的规则,可以写一个解析程序,将声明翻译文自然语言。其实这样的解析程序已经被写了无数遍,通常被称为 Cdecl(C declaration)。现在还有这样的在线服务 cdecl.org,输入前面的例子 char * const *(*next)();,会得到下面的结果:
declare next as pointer to function returning pointer to const pointer to char
妈妈再也不用担心我看不懂 C 的声明了!
# 关于 const
const 并不一定代表常量,它表示被它修饰的对象为“只读”。
涉及指针和 const 的声明有几种可能的顺序:
|
|
根据优先级规则 C,前面两种情况,const 作用于类型说明符 int,表示指针所指向的对象为只读:
|
|
最后一种情况,const 作用于左边的指针星号,表示指针本身是只读的:
|
|
如果想指针和指针所指向的对象都为只读,可以使用下面的声明:
|
|
实际上,const 最常见的使用场景是,当函数的参数为指针时,将指针指向的对象设置为只读。例如 strcpy 的原型声明如下:
|
|
const 表明了 strcpy 设计者的意图,src 作为输入,它指向的对象是只读的,不会被 strcpy 修改。
搞懂了 C 语言的声明,下面再看看指针和数组的关系。
# 指针和数组
# 数组与指针截然不同
在 C 语言中,数组和指针是截然不同的两种东西:
数组是相同类型的对象排列而成的集合,而指针的值是地址,表示指向某处。
但在很多情况下,数组和指针又可以互换使用,这让初学者感到困惑,到底它们什么时候是相同的,什么时候必须严格区分不能混淆?数组和指针这种微妙的关系,是造成指针成为难点的另一个重要原因。
我们分别从“声明”和“使用”这两种情况考虑:
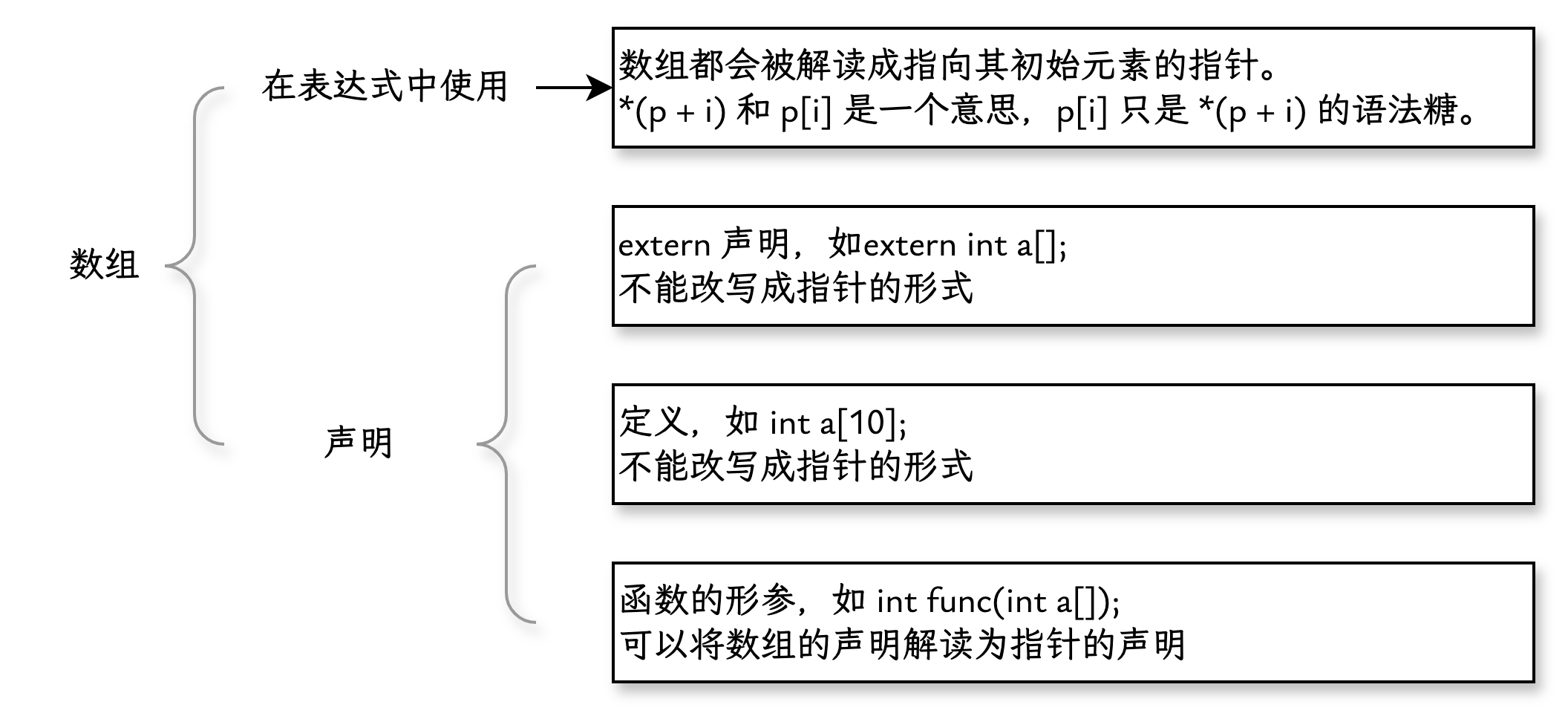
数组和指针可以在下面两种情况下互换使用:
- 在表达式中使用时
- 在声明函数形参时
其他情况下,两者不能混淆。
# 什么时候数组与指针相同
# 在表达式中
根据 ANSI C 标准,在表达式中,数组名会被编译器解释为指向数组第一个元素的指针。因此,代码可以像这样写:
|
|
在表达式中,数组名 array 被视为“指向数组第一个元素的指针”,将它赋值给指针 p 后,p 也指向数组的第一个元素。
要访问数组的第二个元素,可以使用下标运算符 []:
|
|
其实在表达式中,下标运算符 [] 与数组无关,它的含义是“从指针指向的地址开始,加上偏移量,取出该位置的值”。编译器会将 array[i] 转换为 *(array + i),这两种形式是等价的,array[i] 只是 *(array + i) 的简化写法。例如,以下两种方式都能访问数组的第二个元素:
|
|
由于在表达式中,数组名 array 相当于指向数组首元素的指针,所以同样可以通过指针 p 来访问数组元素:
|
|
因此,可以说在表达式中,数组和指针是等价的,可以互换使用。
另外,下标运算符[] 具备交换性,就像加法操作符一样,可以交换两个操作数的位置,保持意义不变,下面两种形式都是正确的,访问数组的第二个元素:
|
|
# 左值
虽然在表达式中,array 确实被解释为指针,但它本身不能被赋值修改。下面的代码会导致错误:
|
|
提示的错误信息为:“expression must be a modifiable lvalue”。那么,lvalue 是什么意思呢?
首先,我们来理解错误信息中的“expression(表达式)”。表达式由运算符和操作数组成,能够通过计算返回一个结果,且可能会产生副作用(如修改变量值)。标识符、常量等属于基本表达式,多个表达式通过运算符连接仍然构成表达式。表达式的关键特征是它会产生一个结果。
相比之下,C 语言中有许多不产生值的语句,比如控制语句和声明语句。而在 Rust 中,几乎所有东西都是表达式,包括控制结构和赋值操作。
接下来,我们来看看什么是左值。变量名在不同上下文中有两种含义:既可以表示地址,也可以表示该地址中存储的内容。例如:
|
|
在这条赋值语句中,p 表示一个内存地址,array 表示存储在该地址中的值。当变量名出现在赋值语句的左边时,它代表一个内存地址,称为左值;出现在右边时,它代表内存地址中的内容,称为右值。
编译器在编译时会为每个变量分配地址,这个地址在编译时是已知的,而变量中的值只有在运行时才能确定。因此,左值在编译时是已知的,而右值要到运行时才可得知。
左值可以被修改,意味着它能出现在赋值语句的左边,可以向该位置存入数据。右值则不能被修改,不能直接赋值给它:
|
|
数组名在表达式中被解释为指针,即表示内存中的位置,但它是不可修改的左值。这是因为数组名实际上是一个常量指针,表示数组起始位置的地址,而不是一个可以修改的内存位置。因此,不能对数组名进行赋值操作。不过,虽然数组名本身不可修改,数组的元素却是左值,可以通过数组名和索引来访问和修改这些元素。
最后,回到那个错误信息:“expression must be a modifiable lvalue”,它的意思是,表达式必须是一个可修改的左值。而数组名是不可修改的左值,因此会导致编译错误。
# 例外情况
从前面的介绍我们已经知道,在表达式中,数组和指针是等价的,可以互换使用,但该规则有下面三种例外情况。
- 当数组名作为
sizeof运算符的操作数时
在数组名作为 sizeof 运算符的操作数的情况下,将数组名解读为指针这一规则是无效的,在这种情况下返回的是数组整体的长度。
- 当数组名作为
&运算符的操作数时
在数组名前加上 & 之后,返回的就是指向数组整体的指针,而不是初始元素指针的指针。
注意 &array 和 array 的区别。array 表示“指向数组初始元素的指针”,并 &array 表示“指向数组的指针”。实际声明一个指向数组的指针:
|
|
如果执行下面这样的赋值,编译器会报出警告。
|
|
这是因为,“指向 int 的指针”与“指向 int 的数组的指针”是不同的类型。
array 和 &array 指向的是相同的地址。那么它们到底有何不同呢?那就是在使用它们进行指针运算时,结果不同。array + 1 前进 4 个字节(假设 int 类型的长度是 4 个字节),而 array_p + 1 则前进 4 * 3 个字节。
- 初始化数组时的字符串字面量
用双引号括起来的字符串被称为 字符串字面量(string literal)。字符串字面量的类型实际上是“char 数组”,因此在表达式中,它会被解读为指向 char 类型的指针。
|
|
当用字符串字面量来初始化 char 数组时,编译器会进行特殊处理。它会将字符串字面量视为一个省略了花括号的字符列表。也就是说,编译器会将 "abc" 这样的字符串字面量视为 { 'a', 'b', 'c', '\0' } 这样的字符数组。以下两种初始化方式是等价的:
|
|
需要注意的是,这种处理方式只在数组初始化时适用,所以以下写法是不合法的:
|
|
如果初始化的不是 char 数组,就不会触发这种特殊处理:
|
|
在这种情况下,"abc" 是一个 char 数组,因为它出现在表达式中,所以会被解释为指向该数组首元素的指针,进而被赋值给 str。
# 函数的形参声明
在 C 语言中,数组不能被整体操作,也就是说,不能直接将一个数组赋值给另一个数组,或者将数组作为参数传递给其他函数。那么,如果我们想把一个数组传递给函数,该怎么做呢?可以通过传递指向数组首元素的指针来实现。
在函数形参的声明中,编译器会将数组的形式自动改写为指向数组第一个元素的指针。编译器实际上只会将数组的地址传递给函数,而不是传递整个数组的副本。
下面几种形参声明方式都是等价的:
|
|
模式 2 与模式 3 是模式 1 的语法糖。即使像模式 3 写上元素个数,编译器也会无视。不管选择哪种方法,在函数内部事实上获得的都是一个指针。
也就是说,在函数的形参声明中,无法声明一个真正的数组,只能声明指针,即使写成数组的形式,编译器也当做指针对待。
前面介绍过,在表达式中,数组名会被解读为指向数组初始元素的指针。在调用函数的时候,传递给函数的实参是表达式,因此数组名会被解读为指向数组初始元素的指针。同时,在函数的形参声明中,声明的数组都会被改写为指向数组初始元素的指针。这两个规则完美的契合,让我们在把数组作为实参传递给函数时,实际上传递的是数组首元素指针的副本,符合了函数的形参声明。在函数内部,可以通过指针访问数组的元素,因为在表达式中,指针和数组是等价的,可以互换使用,a[i] 只是 *(a + i) 的简化写法。
# 什么时候数组和指针不能混淆
除了函数形参的声明以外,数组的声明就是数组,指针的声明就是指针,两者不能混淆。
# 数组的定义
定义是声明的一种特殊情况,它分配内存空间,并可能提供一个初始值。
数组定义分配了一块连续的内存空间,而指针定义只分配了存储一个地址的空间。它们在定义时各有其用途,不能混为一谈。例如:
|
|
上面的 array 是实际分配了空间的数组,而 ptr 只是一个指针,它可以指向某块内存但本身并不分配任何数据存储空间。
# 外部数组的声明
在多个编译单元(如多个 .c 文件)中使用 extern 声明全局变量时,数组和指针必须严格区分。如果在一个文件中定义了一个数组,但在另一个文件中错误地将它声明为指针,程序可能会产生不可预期的错误,甚至崩溃。例如在 file_1.c 中:
|
|
在 file_2.c 中:
|
|
file_1.c 定义了数组 a,但在 file_2.c 声明它为指针。即使用链接器将它们结合起来,程序也还是不能运行。因为 file_2.c 把原本是 int 数组的 a 的前 8 个字节解释成了指针,并引用了它指向的内容,这样的程序当然会崩溃。
# 多维数组
理论上,多维数组(Multidimensional Array)和数组的数组(Array of Arrays)是完全不同的概念。多维数组是一个真正的、在内存中连续存储的矩阵式结构,而数组的数组本质上是多个一维数组的嵌套。
在某些编程语言中(例如 C#),两者之间有着严格的区分。然而,在 C 语言中并不存在真正意义上的“多维数组”。我们看到的类似多维数组的结构,其实是“数组的数组”。例如,以下声明:
|
|
arr 是一个包含 3 个元素的数组,其中每个元素都是一个长度为 4 的一维数组。换句话说,arr 是一个数组,里面的每个元素又是一个数组,形成了二维结构。
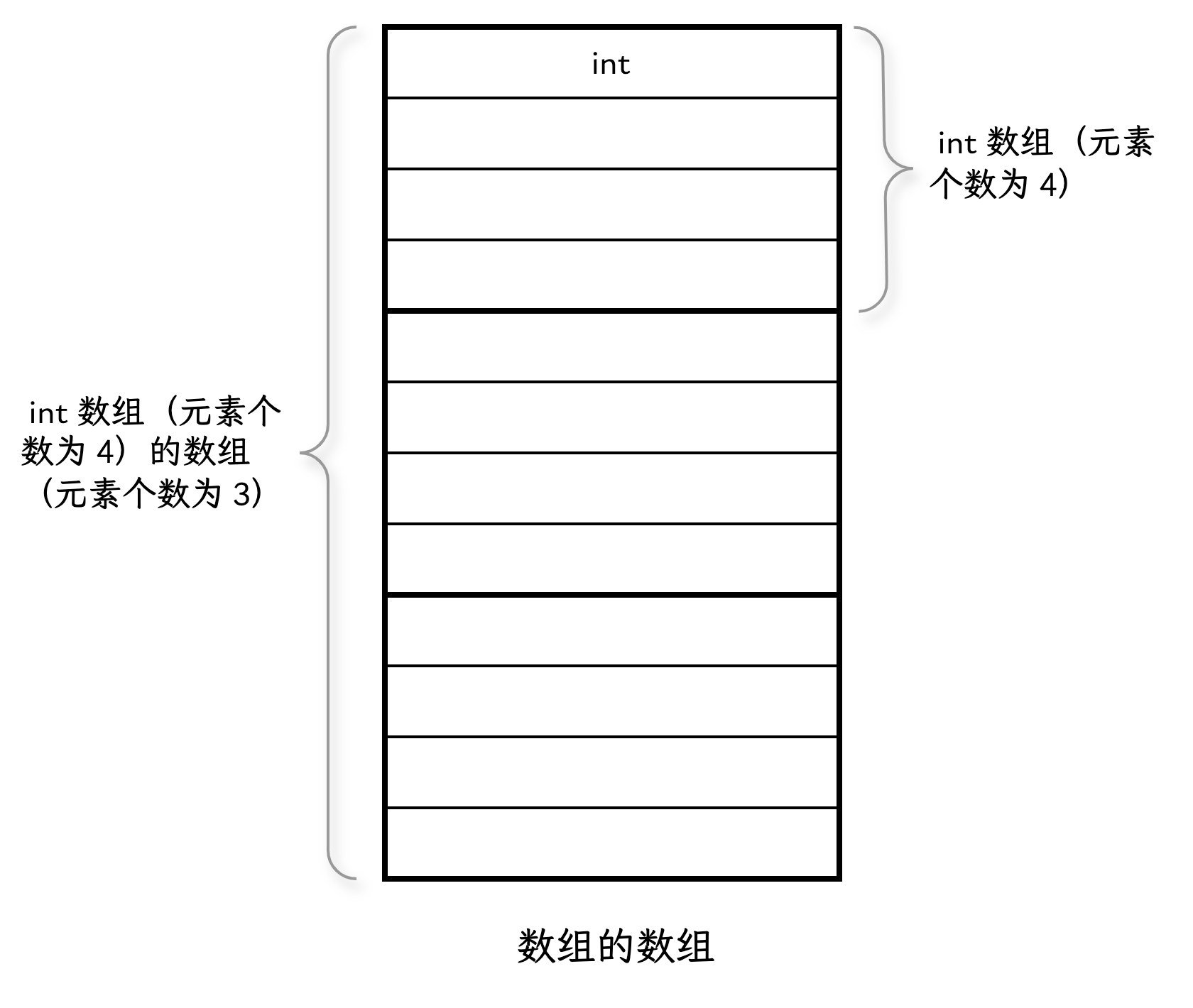
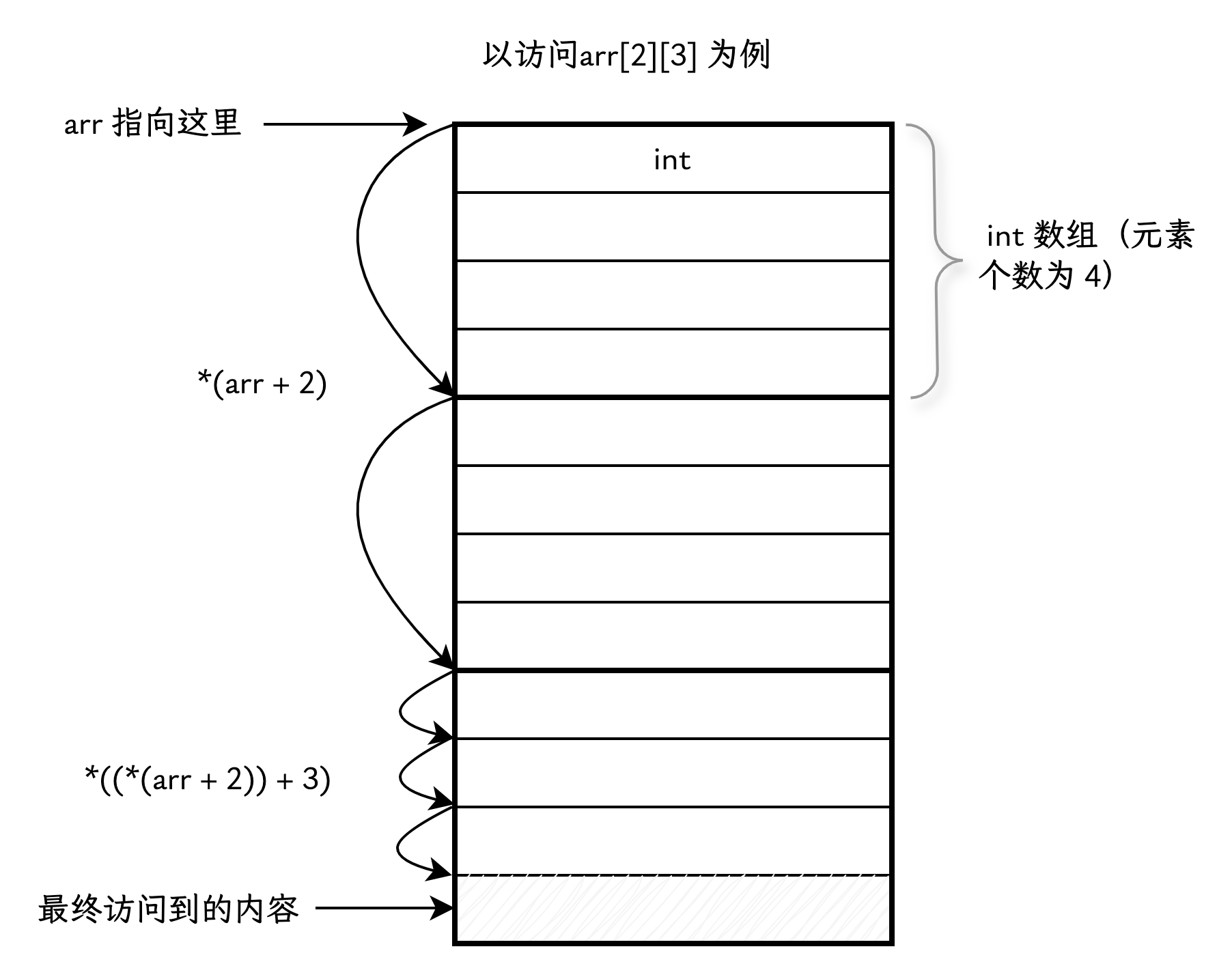
那么,arr[i][j] 是如何访问数组元素的呢?
由于在表达式中,数组名会被解读为指针,因此 arr 被看作是“指向包含 4 个元素的 int 数组的指针”(即 int (*)[4])。
arr[i] 实际上是 *(arr + i) 的简化形式。表达式 arr + i 代表指针前进了 sizeof(int[4]) * i 个字节的距离。
*(arr + i) 的类型是一个 int 数组,但在表达式中,数组名又会被解读为指针。因此,*(arr + i) 会转换为“指向第 i 行的 int 数组的首元素的指针”。这意味着 (*(arr + i))[j] 实际上等价于 *((*(arr + i)) + j),也就是对该行的首地址偏移 j 个位置,最后得到的元素内容,类型为 int。
# 关于空的下标运算符 []
前面已经介绍过,当数组作为函数的形参时,可以省略下标运算符 [] 中的元素个数。除此之外,还有几个特殊情况也允许使用空的下标运算符 []。
- 函数形参的声明
在函数的形参中,只有最外层的数组会被解读为指针。即使在声明中写了元素个数,编译器也会忽略它。
- 通过初始化列表确定数组长度的情况
编译器可以根据初始化列表推导出数组的长度,因此在这种情况下,最外层数组的元素个数可以省略。
|
|
- 使用
extern声明全局变量
当全局变量只在一个编译单元(.c 文件)中定义,而在其他代码文件中通过 extern 声明时,最外层数组的元素个数可以省略。因为数组的实际长度要在链接时才能确定,所以在 extern 声明时,省略数组长度是合法的。
- 结构体的柔性数组成员
从 C99 开始,结构体的最后一个成员可以使用柔性数组,即可以用空的 [] 表示其长度。这种数组在实际使用时由运行时的分配情况决定。
|
|
# 指向函数的指针
在 C 语言中,函数名在表达式中会自动转换为指向该函数的指针,但有两个例外:当它作为地址运算符 & 或 sizeof 的操作数时,函数名保持为函数本身。
函数调用运算符 () 的操作数实际上并不是函数名本身,而是指向函数的指针。这意味着函数名和指向函数的指针是可以互换使用的。
一个值得注意的点是,尽管你可以对指向函数的指针使用间接运算符 *,它并不会改变实际的行为。即使将 * 应用于指向函数的指针,它仍会立刻被转换回指向函数的指针。因此,即便你通过多层间接访问函数指针,代码依然能够正常运行。
例如,以下代码使用了多层间接访问,但它依然等同于直接调用 printf:
|
|
这揭示了一个有趣的现象:指向函数的指针在 C 中相当灵活,也使得函数指针的语法有些独特,但其行为仍然遵循 C 语言中表达式的规则。
# 指针的基本用法
现在我们已经能解读复杂的 C 声明,并理解了数组和指针之间的微妙关系。你可能会问:为什么一定要使用指针?或者说,指针到底有什么用处?接下来,我们将介绍 C 语言中指针的几个基本用法。要用 C 语言编写实用的程序,指针的使用是不可避免的。
# 从函数返回多个值
C 语言的函数只能返回一个值,我们可以通过使用指针突破这个限制,实现从函数返回多个值的效果。具体做法是将指针作为参数传递给函数,让函数修改指针所指向的对象的值。
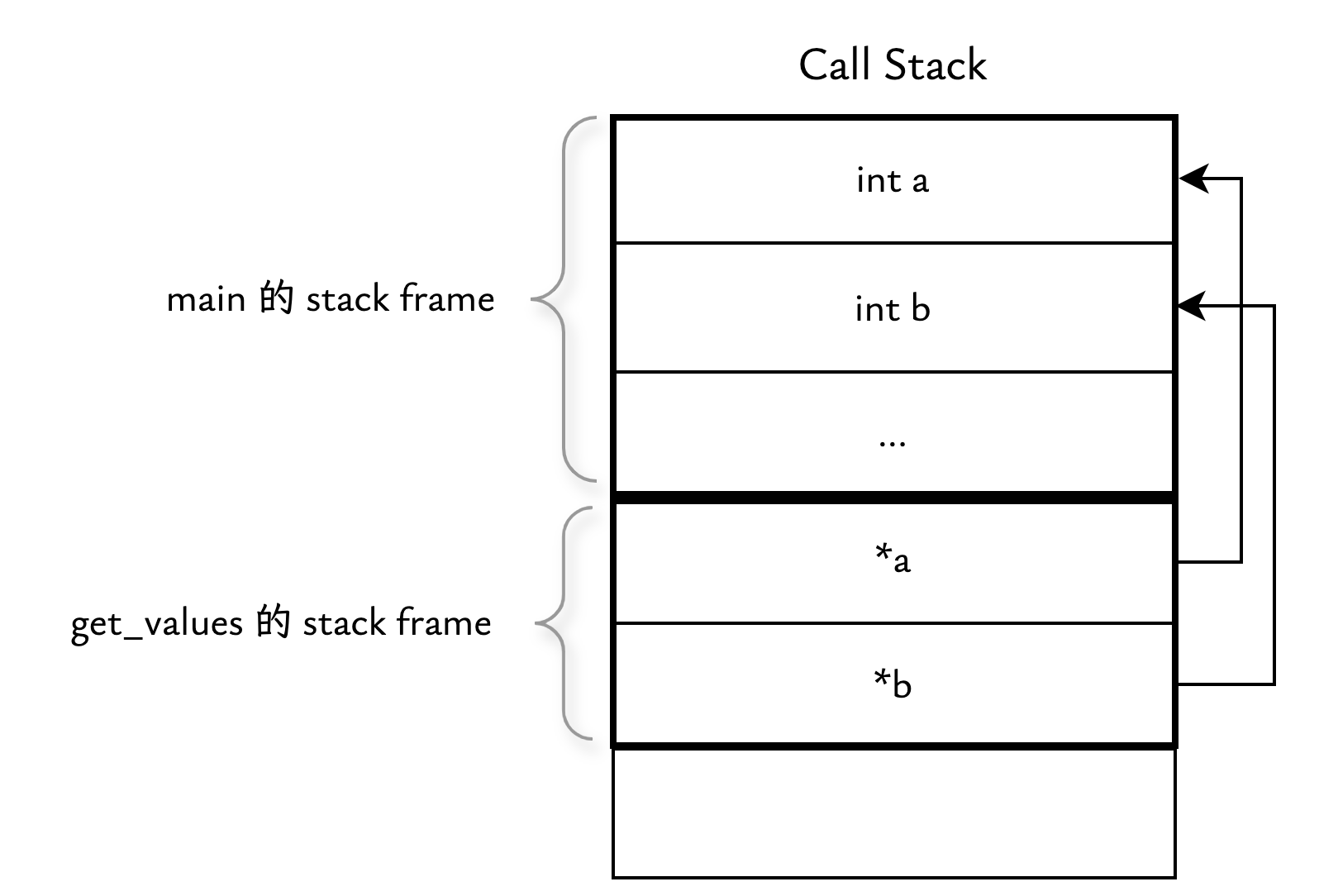
假设我们需要返回的数据的类型为 T ,则参数类型为 T *,即"指向 T 的指针"。下面是一个简单的示例,展示了如何通过指针从函数返回两个整数值:
|
|
在 C 语言中进行函数调用时,参数是作为值传递的,被称为值传递(call by value),也就是说,实参的值会被复制调用方函数到形参中,然后形参就可以像普通的局部变量一样使用了。
在上面示例中,get_values 的参数的类型是“指向 int 的指针”,调用时仍然是值传递,只不过复制到形参的值,是 a 和 b 的地址。这样,在 get_values 内部就可以通过指针修改 a 和 b 的值了。
# 将数组作为参数传递
在 C 语言中其实是不可以将数组作为参数传递的,但是通过传递指向数组初始元素的指针,可以达到与传递数组相同的效果。
如下面的示例程序:
|
|
前面说过,在 C 语言中,参数全部都是通过值传递的,传递给函数的都是它的副本。对于实参是数组的情况也是一样的,只不过传递的是数组首元素指针的副本。
在 main 中调用 print_array 时,由于函数的实参 array 在表达式中,所以 array 会被解读为指向数组初始元素的指针,然后这个指针的副本会被传递给 print_array。在函数内部,指针可以像数组一样,使用 array[i] 这样的形式访问数组的元素,因为 array[i] 只不过是 *(array + i) 的语法糖。
另外,print_array 还需要通过参数 size 来接收数组的长度。因为对于 print_array 来说,array 只是一个指针,它无法知道调用方传递的数组的长度。
回想上一节介绍的,将指针作为参数传递给函数,在函数内部通过指针修改指向的值,达到从函数返回多个值的效果。当数组作为参数传递给函数时,默认传递的就是指向数组的指针,所以在函数内部通过指针修改的和调用方是同一个数组。
# 多维数组作为参数传递
正如前面介绍的那样,当数组被用作函数形参时,数组的声明会自动被解释为指针的声明。例如:
|
|
实际上等价于:
|
|
即使在声明中显式写上元素个数,比如 void func(int a[10]),编译器仍会忽略数组的大小信息,只会将其视为指向 int 类型的指针。
那么如果形参是多维数组呢?来看下面的函数声明:
|
|
在这里,a 的类型是“int 的数组的数组”,但由于它是函数形参,编译器会将其解读为“指向一个长度为 4 的 int 数组的指针”:
|
|
这与一维数组的情况类似。即便你在声明中指定了最外层数组的大小,比如:
|
|
编译器同样会忽略外层数组的长度信息,将其视为“指向包含 4 个元素的 int 数组的指针”。
在多维数组(即“数组的数组”)中,只有最外层的数组会被解读为指针。这意味着在函数形参中,除了最左边的一维数组外,所有内层数组的维度大小必须显式指定。这是因为在进行地址运算时,编译器需要知道每一维数组的长度,以便正确计算内存中的偏移量。
# 动态数组
C 语言中的数组,在编译时必须知道数组的长度。虽然 C99 中引入了变长数组(VLA),但它只能用于自动变量,函数结束后数组自动释放。如果想让数组的生命周期跨域多个函数调用,就需要使用动态内存分配。
通过 malloc 可以在运行时分配所需大小的数组。例如下面的示例程序,根据用户输入的长度动态分配数组:
|
|
需要注意的是,使用 malloc 分配的动态数组,程序员必须自己管理数组元素的个数。使用完毕后,需要通过 free 函数释放内存。
相对比在 Java 中,数组都是分配在堆上的,new int[10];就相当于 C 中的 malloc(10 * sizeof(int));,并且 Java 有垃圾回收机制自动管理内存。
# 动态数组的数组
前面介绍过,C 语言中的多维数组其实是“数组的数组”。假设某部门有 10 名员工,我们可以使用一个二维数组来存储每位员工的住址:
|
|
这里,addresses 是一个 10x100 的字符数组,其中第一维代表员工人数,第二维代表每个住址的最大长度。由于住址的长度不固定,这种预设的最大长度会导致潜在的内存浪费。因此,使用“动态数组的数组”会是更优的选择。
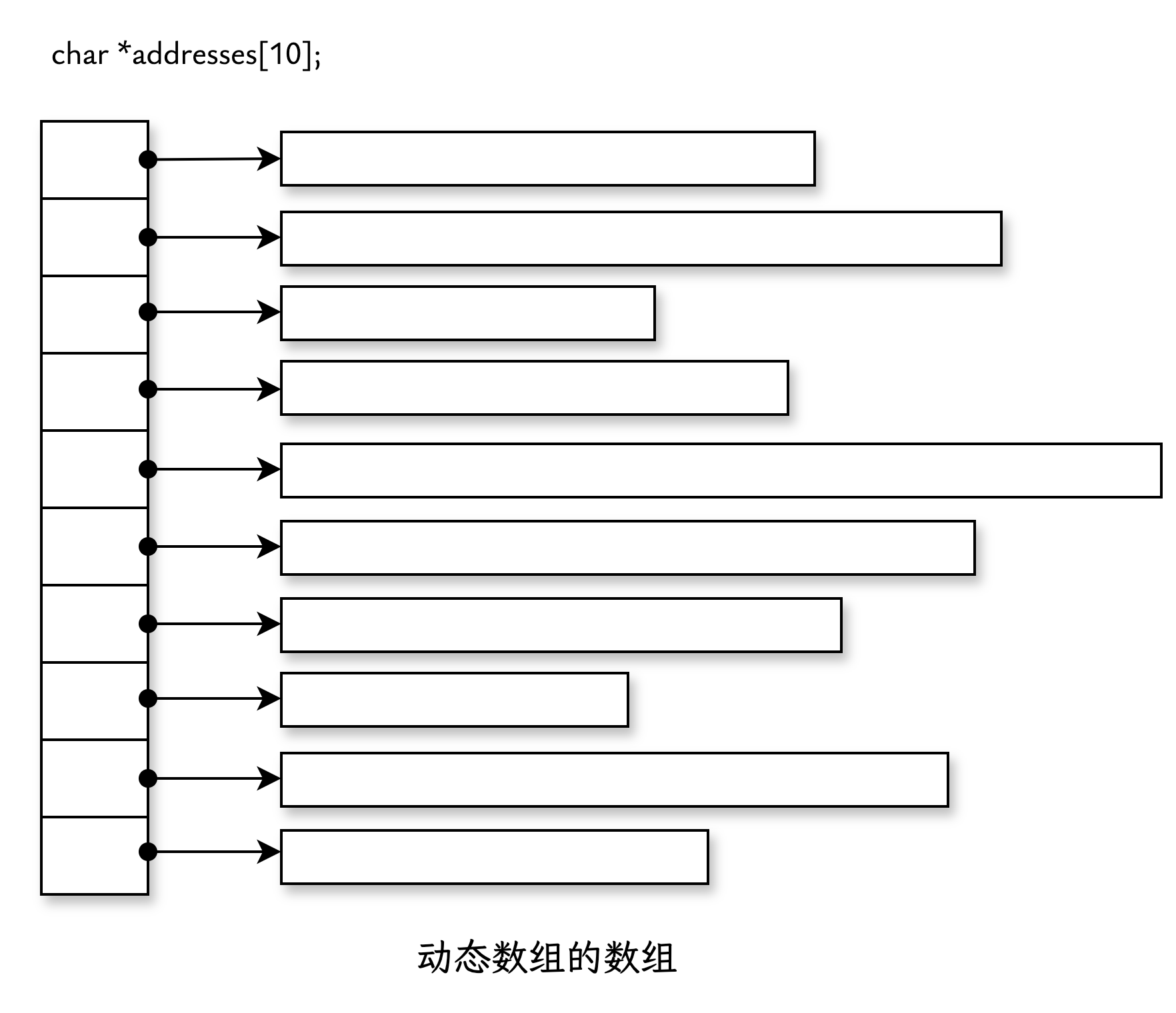
如果员工人数固定为 10,可以使用“动态数组的数组”来高效地存储每位员工的住址,每行的存储空间根据实际输入动态分配:
|
|
在这种情况下,addresses 是一个包含 10 个指针的数组,每个指针都指向一个动态分配的字符数组,用来存储具体的住址。
完整的示例程序如下:
|
|
注意到 read_addresses 函数的参数是 char **addresses。我们想传递给 read_addresses 的是一个 char * 数组,即 char *addresses[10],但在函数形参的声明中,数组都会被改写为指针,因此即使函数声明为 void read_addresses(char *addresses[10]),编译器也会改写为 void read_addresses(char **addresses)。
动态数组的数组 addresses 的内存布局如下:
# 动态数组的动态数组
在上一节中,我们使用 char 的动态数组来存储每个员工的住址,但假设员工人数是固定的。如果员工人数不固定,我们就需要使用“动态数组的动态数组”。
|
|
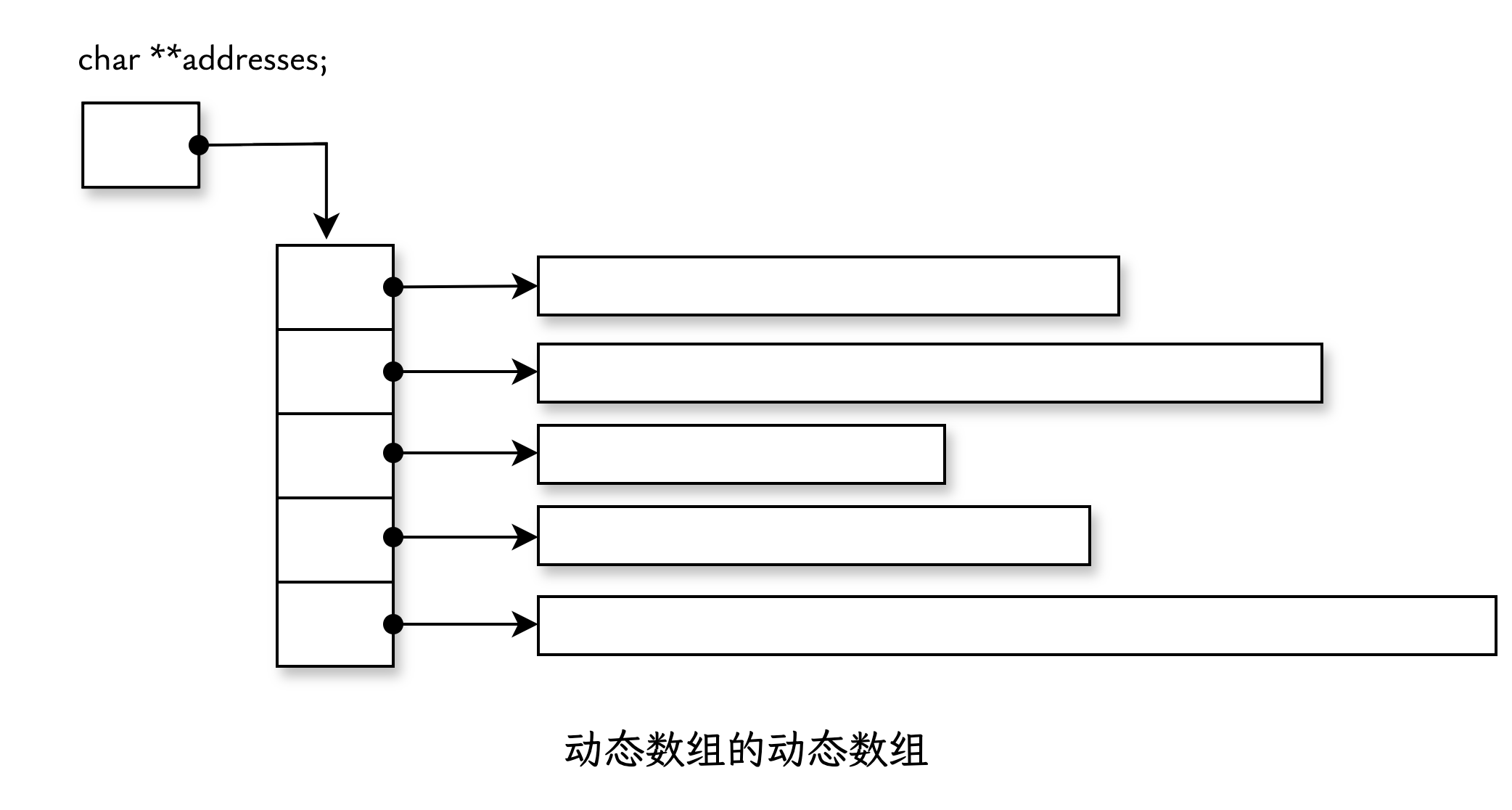
“类型 T 的动态数组”可以通过“指向 T 的指针”来实现。因此,要获取“T 的动态数组的动态数组”,只需使用“指向 T 的指针的指针”。
下面是一个完整的示例程序,要求用户先输入员工人数,再逐个输入每位员工的住址:
|
|
动态数组的动态数组 addresses 的内存布局如下:
对于上面的示例程序,我们注意到一个细节,用于存储员工住址的 addresses,是在调用 read_addresses 函数之前分配的,我们稍加修改,就可以在 read_addresses 函数内部分配 addresses 的内存:
|
|
这时 read_addresses 函数的参数变成 char ***addresses。下面是这两种情况的内存布局对比:
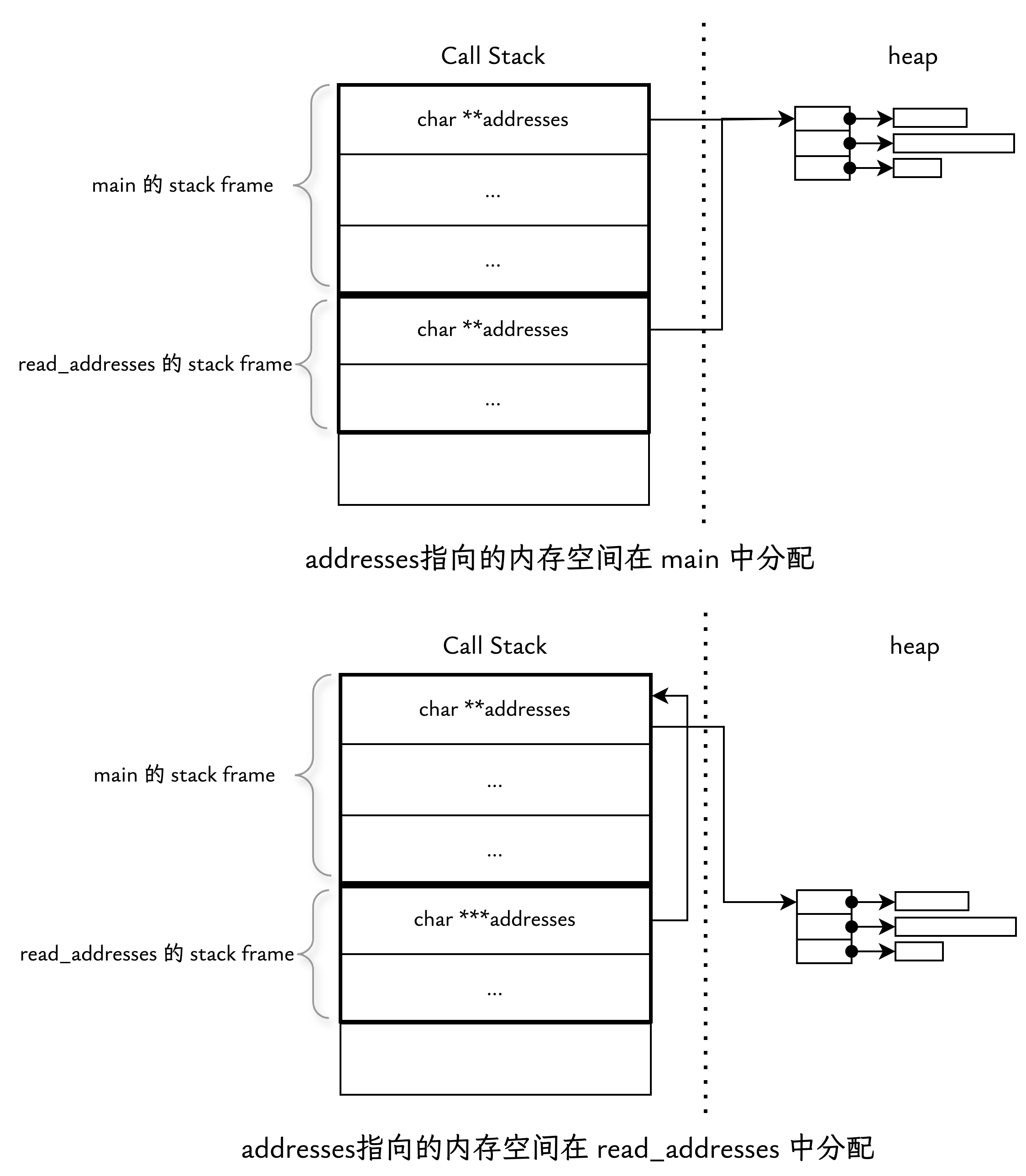
C 语言中参数都是通过值传递的。对于第一种情况,addresses 指向的空间在 main 中分配,调用 read_addresses 函数时,传递给 read_addresses 的是 addresses 的副本,它们都指向 heap 中同一块内存的指针,因此在 read_addresses 函数内部通过 addresses 对这块空间的修改,在 main 中同样能看到。
对于第二种情况,动态数组的内存是在 read_addresses 函数中分配,在 main 中调用 read_addresses 函数时,传递给 read_addresses 的是 addresses 指针的副本,即 &addresses,类型为 char ***。在 read_addresses 函数内部通过 *addresses 访问的是 main 中 addresses 变量,不管是为 *addresses 分配内存空间,还是通过 *addresses 修改内存中的值,都是间接修改 main 中 addresses 指向的值。
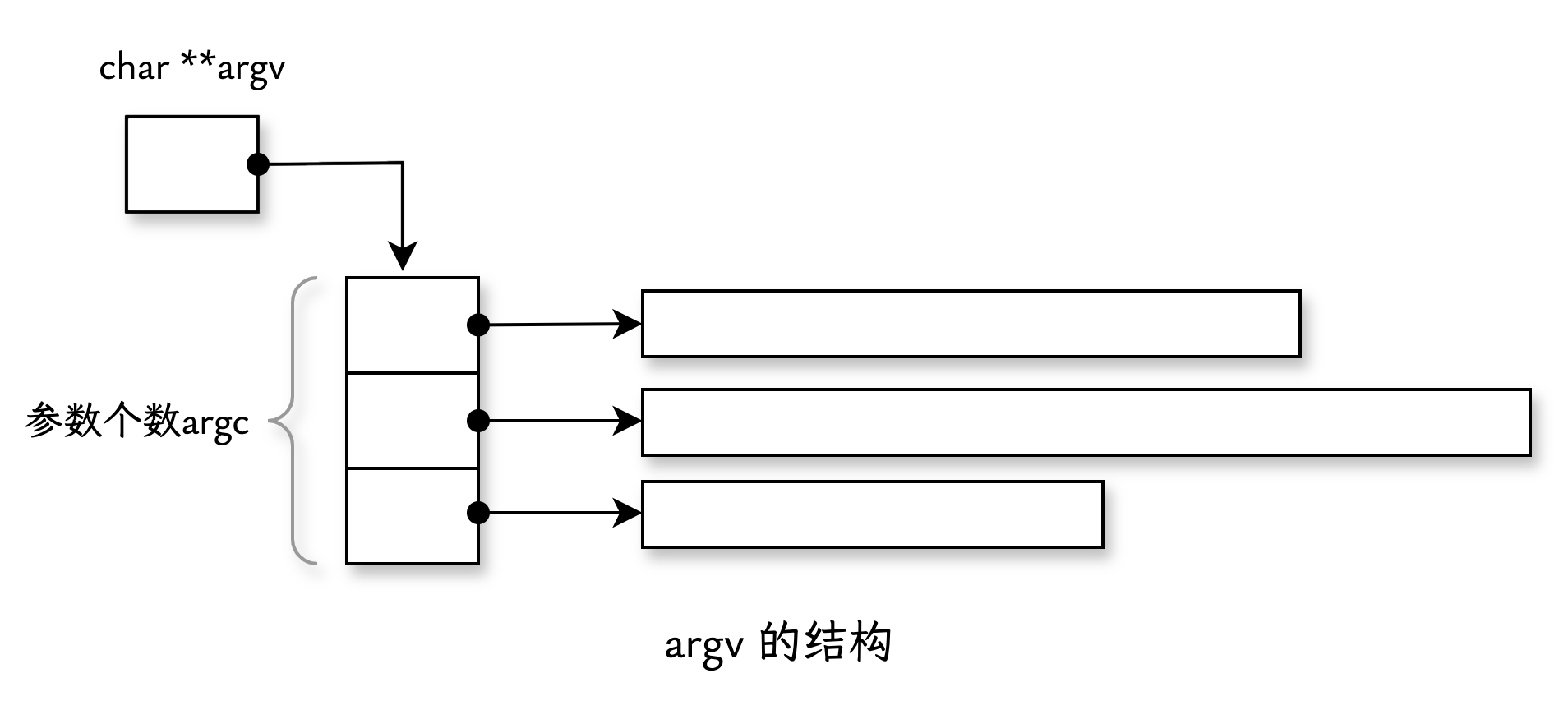
# 命令行参数
实际上命令行参数就是一个“char 的动态数组的动态数组”。在 main 函数的定义中:
|
|
argc表示命令行参数的个数。argv是一个char *类型的数组,其中每个元素指向一个命令行参数字符串。
由于在函数的参数列表中,数组会被视作指针,所以写成下面这样也是一样的:
|
|
argv[i] 指向每个命令行参数字符串(长度不固定),而 argv 的大小会随着实际参数数量动态调整。
# 通过参数返回指针
前面介绍过,如果想通过参数返回类型 T,则参数类型为 T *,即“指向 T 的指针”。那么如果想通过参数返回“指向 T 的指针”,则参数类型为 T **,即“指向 T 的指针的指针”。
什么情况下会用到通过参数返回“指向 T 的指针的指针”呢?一种场景是,如果函数需要改变调用者传入的指针本身,使其指向新的内存区域,可以使用“指向 T 的指针的指针”,即(T **)作为参数。
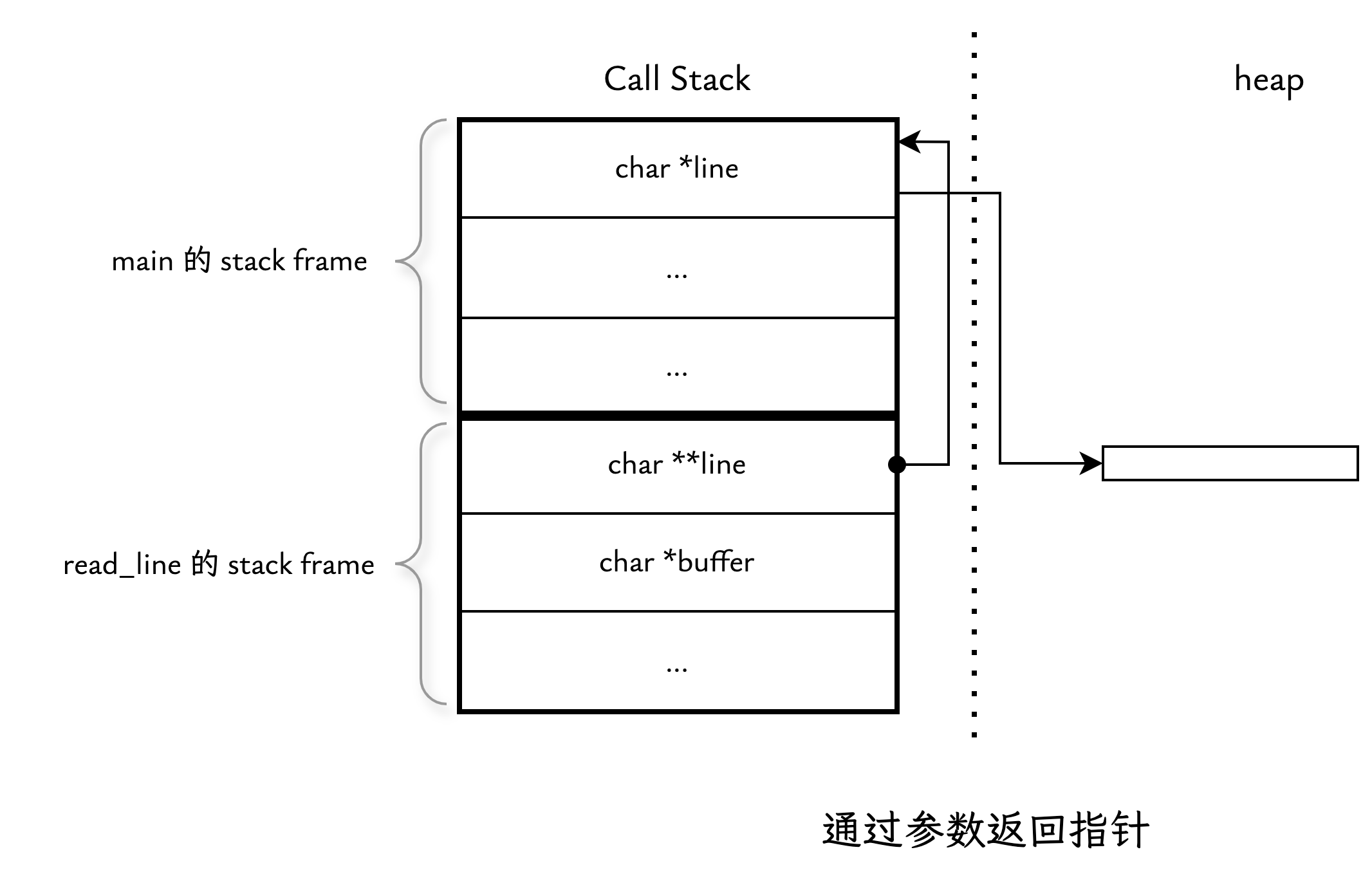
例如我想实现一个 read_line 函数,通过返回值来表示处理状态,例如正常读取、文件结尾,或因内存不足而失败等情况。由于函数只能有一个返回值,因此需要通过参数返回读取的结果指针。此时,如果我们希望返回的是 char 类型的指针,那么参数的类型就应是“指向 char 的指针的指针”(即 char **)。下面是完整的示例程序:
|
|
在 main 中定义的变量 line 类型为“指向 char 的指针(char *)”, read_line 函数内部需要修改 line 本身,使其指向新分配的内存,因此参数类型应该为“指向 char 的指针的指针(char **)”。下面是运行时的内存布局:
# 双指针
双指针”并不是一个严格的标准术语,所谓双指针,其实就是指向指针的指针。

从前面的例子可以看到,双指针主要出现在以下两种场景:
- 动态数组的动态数组,即在多级数据结构中使用动态内存分配
- 通过参数返回指针,需要在函数内部修改指针本身
双指针的多层间接引用可能让代码显得复杂难懂,但只要理解为什么要这样做,其实并不难。一开始可以在纸上画出堆栈和堆的内存布局,这将有助于你更直观地理解双指针的工作原理。
# 纵横可变的二维数组
我们知道,在 C 语言中没有真正的二维数组,只有数组的数组。如何我们需要一个二维数组,两个维度都是在运行时才确定,应该如何做?
前面介绍过“动态数组的数组”和“动态数组的动态数组”,它们的第二维的长度不固定,像锯齿一样,有一个专门的名称叫 Iliffe 向量。
现在我们想要的是,像标准二维数组那样,第二维的长度一致的“数组的数组”,尝试像下面这样做:
|
|
对于 ANSI C 标准,size 必须是一个整型常量表达式,不能运行时再确定。从 C99 开始,size 可以是变量,这称为可变长数组(Variable Length Array,VLA),但 board 必须是自动变量,也就是说只在函数内部有效,函数退出后自动释放。如果希望 board 一直保持到程序退出,则需要使用 malloc() 动态内存分配。
在 C99 中,通过以下写法就可以得到 size×size 的二维数组。
|
|
然后就可以通过 board[i][j] 访问到数组的各个元素。完整的示例程序如下:
|
|
# 数组的动态数组
假设我们需要实现一个画板来记录用户绘制的折线。如何表示这些点呢?我们可以使用 double[2] 来表示画板上的一个点,其中 double[0] 代表 X 坐标,double[1] 代表 Y 坐标。折线由多个点组成,因此我们需要一个 double[2] 的动态数组,实际上就是一个“数组的动态数组”。
|
|
解读一下声明 double (*polyline)[2],polyline 是一个指针,指向一个 double[2] 的数组。
如果我们要获取第 i 个点的坐标,可以通过 polyline[i][0] 和 polyline[i][1] 来访问 X 和 Y 坐标。
使用 double (*polyline)[2] 表示折线可能不够直观,更好的做法是使用结构体:
|
|
在 C99 标准中,引入了“柔性数组成员”(Flexible Array Member, FAM)的特性,这允许结构体的最后一个成员是一个长度可变的数组。上面的结构体 Polyline 就利用了这一特性来定义了一个变长的点数组。
在给 Polyline 分配内存时,需要如下写法:
|
|
通过这种方式,我们可以灵活地管理折线中的点数,使代码在处理动态数组时更具简洁性和可维护性。
# 通用数据结构
前面介绍的指针基本用法,主要是和数组相关,利用了数组和指针之间的微妙关系。这部分是 C 语言的特有的内容,也是指针的难点所在。
大多数编程语言都会用指针(引用)来构造链表、树等通用数据结构,C 语言也不例外。但数据结构知识不是 C 语言特有的,也不是造成指针难懂的原因,因此本文不再赘述,感兴趣的读者可以参考相关数据结构方面的书籍。
# 总结
指针的概念本身并不复杂,但让它成为 C 语言中的难点,主要是由于指针与 C 语言复杂的声明语法交织,以及指针与数组之间的微妙关系。
本文介绍了通过“C 声明优先级规则”表格解析 C 语言声明的方法,现在再复杂的声明对你来说都不是问题。
接着,本文深入剖析了数组与指针的关系,从声明与使用两个方面进行了阐述。只需记住以下两个场景中,数组和指针可以互换使用:
- 在表达式中,数组名会被解释为指向数组第一个元素的指针。因此,
array[i]与*(array + i)是等价的,array[i]只是*(array + i)的简化写法。 - 在函数形参声明中,数组声明会被自动转换为指向数组首元素的指针。
除此之外,数组与指针在其他情况下不可混淆。
此外,本文还介绍了指针的基本用法,包括从函数返回多个值、动态数组、动态数组的数组、动态数组的动态数组,数组的动态数组,纵横可变的二维数组等。这些用法几乎都与数组相关,属于 C 语言特有的内容,也是指针的难点所在。至于指针在链表、树等通用数据结构中的应用,则不属于本文讨论的范围。
希望读完本文后,你已经“看破”指针,对你来说不再是难点。