Kubernetes在2017年赢得了容器编排之战,使得基于容器+Kubernetes来构建PaaS平台成为了云计算的主流方式。在人们把关注的目光都聚焦在Kubernetes上时,容器技术领域在2018年也发生了很多创新,包括amazon最近开源的轻量级虚拟机管理器 Firecracker,Google在今年5月份开源的基于用户态操作系统内核的 gVisor 容器,还有更早开源的虚拟化容器项目 KataContainers,可谓百花齐放。一般的开发者可能认为容器就等于Docker,没想到容器领域还在发生着这么多创新。我在了解这些项目时,发现如果没有一些背景知识,很难get到它们的创新点。我试着通过这篇文章进行一次背景知识的梳理。让我们先从最基本的问题开始:操作系统是怎么工作的?
# 操作系统的工作方式
我们不去讨论操作系统的标准定义,而是想想操作系统的本质是什么,它是怎么为应用提供服务的呢?
其实操作系统很“懒”,它不是一直运行着主动干活,而是躺在那儿等着被中断“唤醒”,然后根据中断它的事件类型做下一步处理:是不是有键盘敲击、网络数据包到达,还是时间片到了该考虑进程切换,或者是有应用向内核发出了服务请求。内核处理完唤醒它的事件,会将控制权返还给应用程序,然后等着再次被中断“唤醒”。内核就是这样由中断驱动,控制着CPU、内存等硬件资源,为应用程序提供服务。
”唤醒“操作系统内核的事件主要分为三类:
- 中断:来自硬件设备的处理请求;
- 异常:当前正在执行的进程,由于非法指令或者其他原因导致执行失败而产生的异常事情处理请求,典型的如缺页异常;
- 系统调用:应用程序主动向操作系统内核发出的服务请求。系统调用的本质其实也是中断,相对于硬件设备的中断,这种中断被称为
软中断。
# CPU的特权等级
内核代码常驻在内存中,被每个进程映射到它的逻辑地址空间:
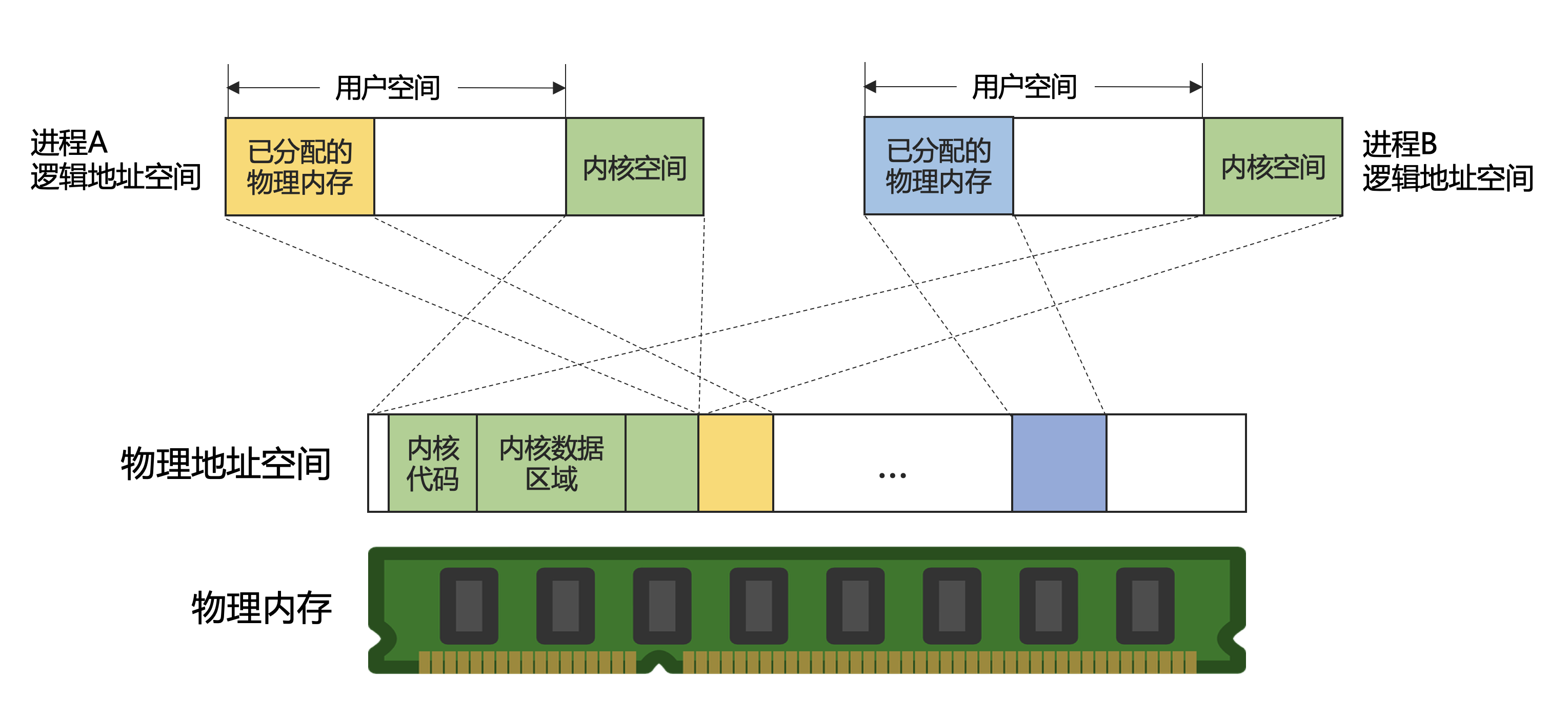
进程逻辑地址空间的最大长度与实际可用的物理内存数量无关,由CPU的字长决定。进程的逻辑地址空间划分为两个部分,分别称为内核空间和用户空间。用户空间是彼此独立的,而逻辑地址空间顶部的内核空间是被所有进程共享。
从每个进程的角度来看,地址空间中只有自身一个进程,它不会感知到其他进程的存在。由于内核空间被所有进程共享,为了防止进程修改彼此的数据而造成相互干扰,用户进程不能直接操作或读取内核空间中的数据。同时由于内核管理着所有硬件资源,也不能让用户进程直接执行内核空间中的代码。操作系统应该如何做到这种限制呢?
实际上,操作系统的实现依赖 CPU 提供的功能。现代的CPU体系架构都提供几种特权级别,每个特权级别有各种限制。各级别可以看作是环,内环能够访问更多的功能,外环则较少,被称为protection rings:
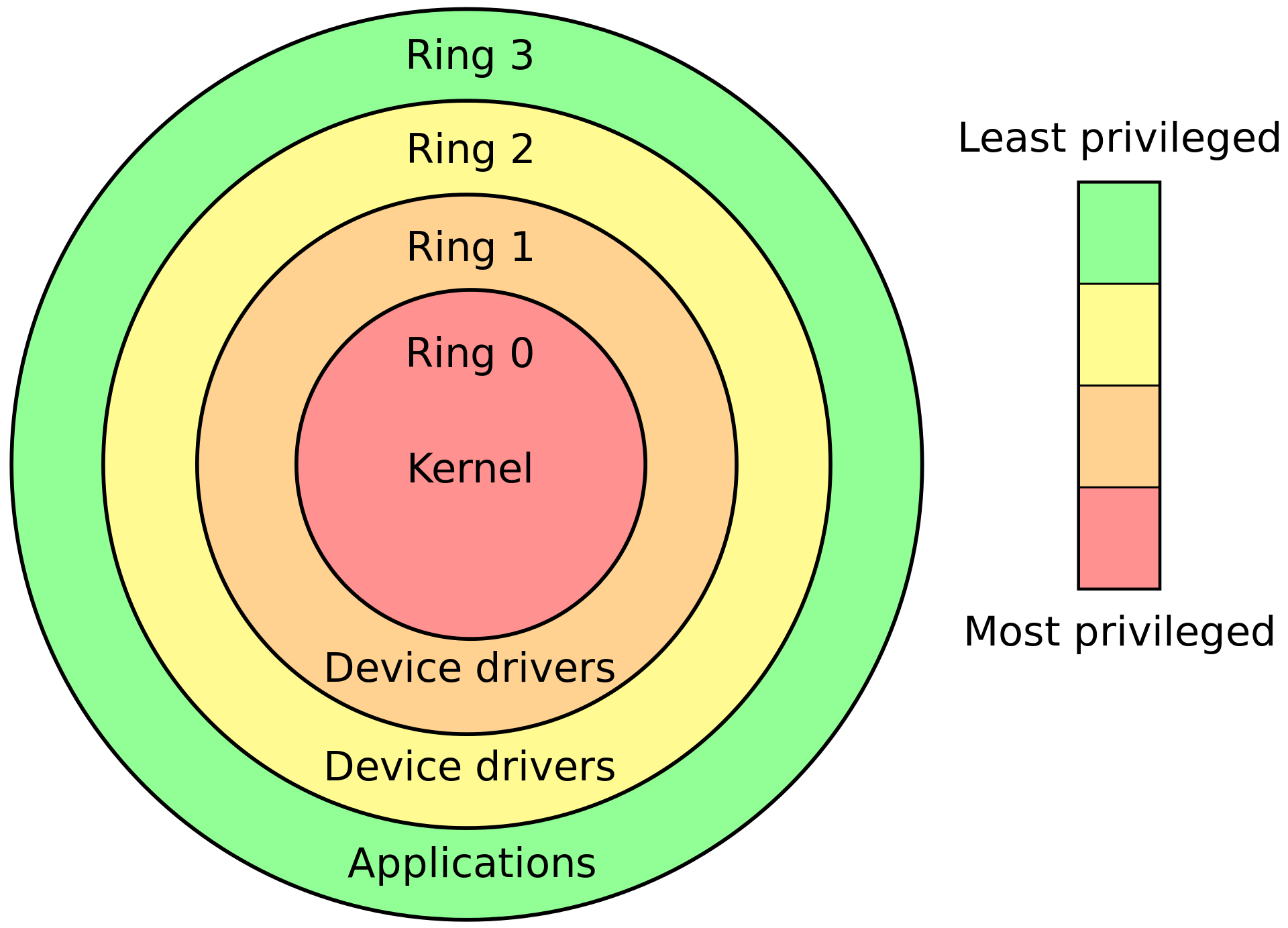
Intel 的 CPU 提供了4种特权级别, Linux 只使用了 Ring0 和 Ring3 两个级别。Ring 0 拥有最多的特权,它可以直接和CPU、内存等物理硬件交互。 Ring 0 被称为内核态,操作系统内核正是运行在Ring 0。Ring 3被称为用户态,应用程序运行在用户态。
# 系统调用
在用户态禁止直接访问内核态,也就是说不同通过普通的函数调用方式调用内核代码,而必须使用系统调用陷入(trap)内核,完成从用户态到内核态的切换。内核首先检查进程是否允许执行想要的操作,然后代表进程执行所需的操作,完成后再返回到用户态。
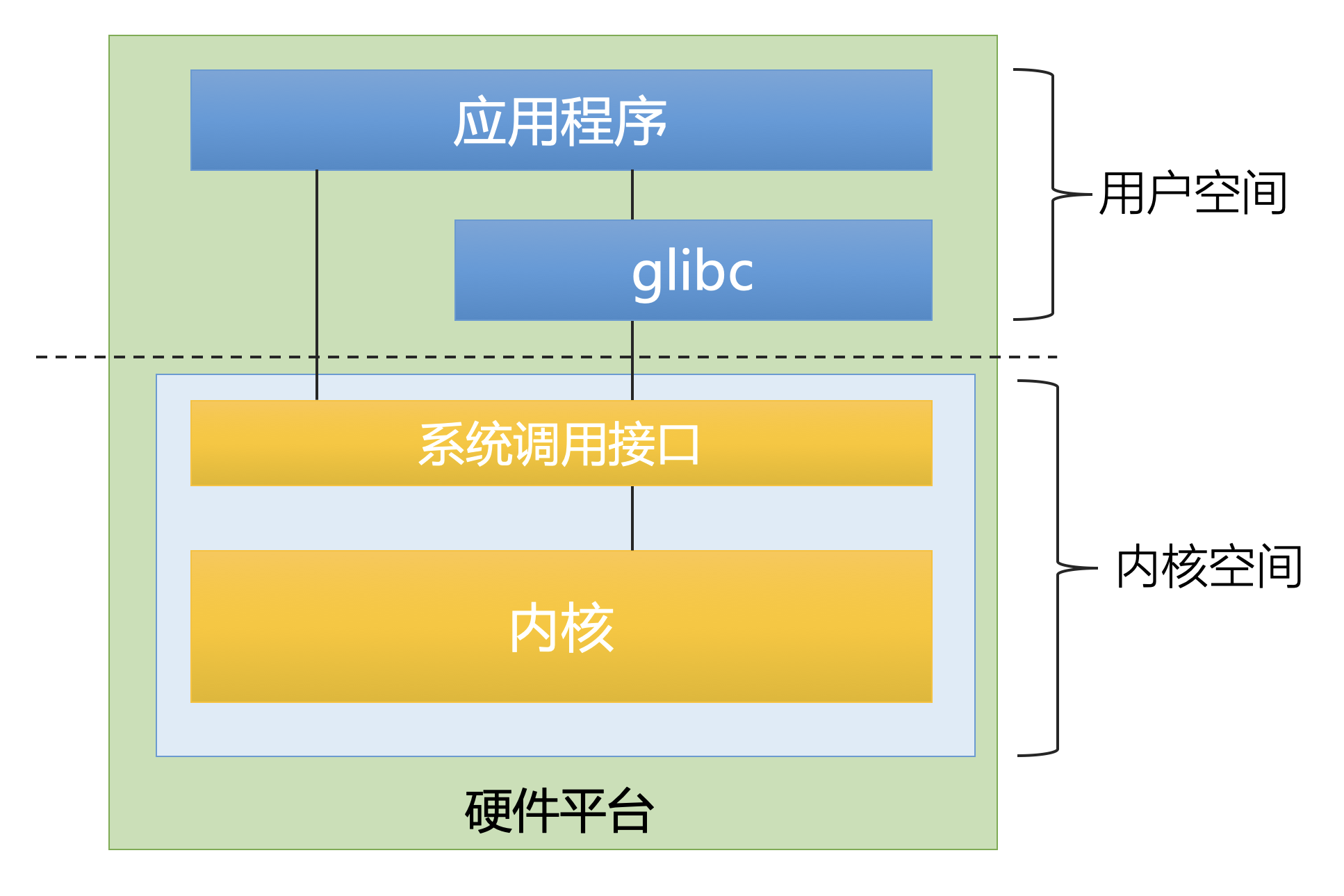
除了代表用户程序执行代码之外,内核还可以由硬件中断激活,然后在中断上下文中运行。另外除了普通进程,系统中还有内核线程在运行。内核线程不与任何特定的用户空间进程相关联。
CPU 在任何时间点上的活动必然为下列三者之一 :
- 运行于用户空间,执行应用程序
- 运行于内核空间,处于
进程上下文,即代表某个特定的进程执行 - 运行于内核空间,处于
中断上下文,与任何进程无关,处理某个特定的中断
# 优化系统调用
从上面的讨论可以看出,由于系统调用会经过用户态到内核态的切换,开销要比普通函数调用大很多,因此在进行系统级编程时,减少用户态与内核态之间的切换是一个很重要的优化方法。
例如同样是实现 Overlay网络,使用 VXLAN 完全在内核态完成封装和解封装,要比把数据包从内核态通过虚拟设备TUN传入用户态再进行处理要高效很多。
对应的也可以从另外一个方向进行优化:使用 DPDK 跳过内核网络协议栈,数据从网卡直接到达用户态,在用户态处理数据包,也就是说网络协议栈完全运行在用户态,同样避免了用户态和内核态的切换。像腾讯开源的 F-Stack就是一个基于DPDK运行在用户空间的TCP/IP协议栈。
了解了操作系统内核的基本工作方式,我们再看下一个话题:虚拟化。
# 虚拟化技术
为了更高效灵活的使用硬件资源,同时能够实现服务间的安全隔离,我们需要虚拟化技术。运行虚拟化软件(Hypervisor或者叫VMM,virtual machine monitor)的物理设施我们称之为Host,安装在Hypervisor之上的虚拟机称为Guest。
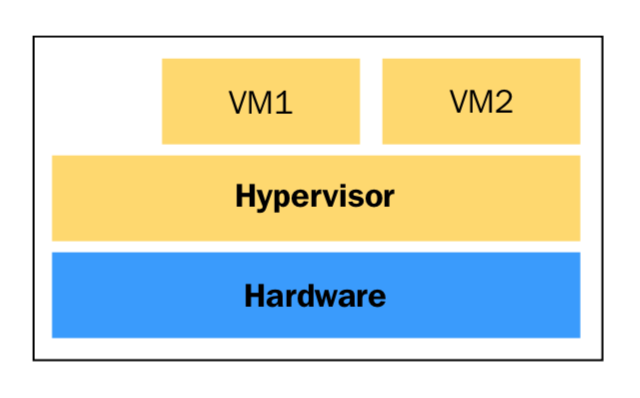
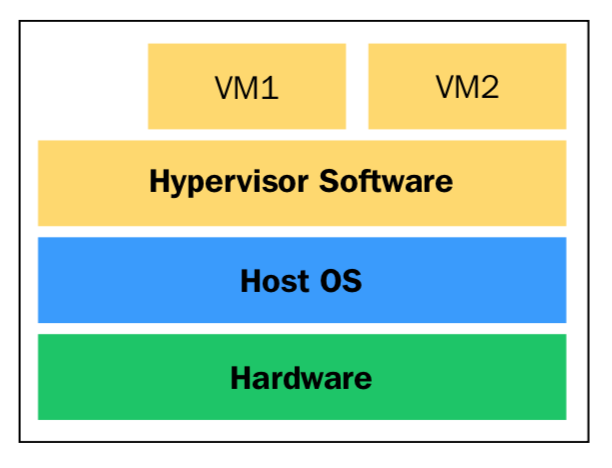
根据Hypervisor在系统中的位置,可以将它归类为type-1或type-2型。如果hypervisor直接运行在硬件之上,它通常被认为是Type-1型。如果hypervisor作为一个单独的层运行在操作系统之上,它将被认为是Type 2型。
Type-1型Hypervisor的概念图:
Type-2型Hypervisor的概念图:
# KVM & QEMU
实际上Type-1和Type-2并没有严格的区分,像最常见的虚拟化软件 KVM(Kernel-based Virtual Machine)是一个Linux内核模块,加载KVM后Linux内核就转换成了Type-1 hypervisor。同时,Linux还是一个通用的操作系统,也可以认为KVM是运行在Linux之上的Type-2 hypervisor。
为了在Host上创建出虚拟机,仅仅有KVM是不够的。对于 I/O 的仿真,KVM 还需要 QEMU的配合。QEMU 是一个运行在用户空间程序,它可以仿真处理器和一系列的物理设备:磁盘、网络、VGA、PCI、USB、串口/并口等等,基于QEMU可以构造出一个完整的虚拟PC。
值得注意的是,QEMU 有两种运行模式:仿真模式和虚拟化模式。在仿真模式下,QEMU可以在一个Intel的Host上运行ARM或MIPS虚拟机。这是怎么做到的呢?实际上,QEMU 通过 TCG(Tiny Code Generator)技术进行了二进制代码转换,可以认为这是一种高级语言的VM,就像JVM。例如可以将运行在ARM上的二进制转换为一种中间字节码,然后让它运行在Host的Intel CPU上。很明显,这种二进制代码转换有着巨大的性能开销。
相对应的,QEMU的另一种是虚拟化模式,它借助KVM完成处理器的虚拟化。由于和CPU的体系结构紧密关联,虚拟化模式能够带来更好的性能,限制是Guest必须使用和Host一样的CPU体系机构。这就是我们最常用到的虚拟化技术栈:KVM/QEMU
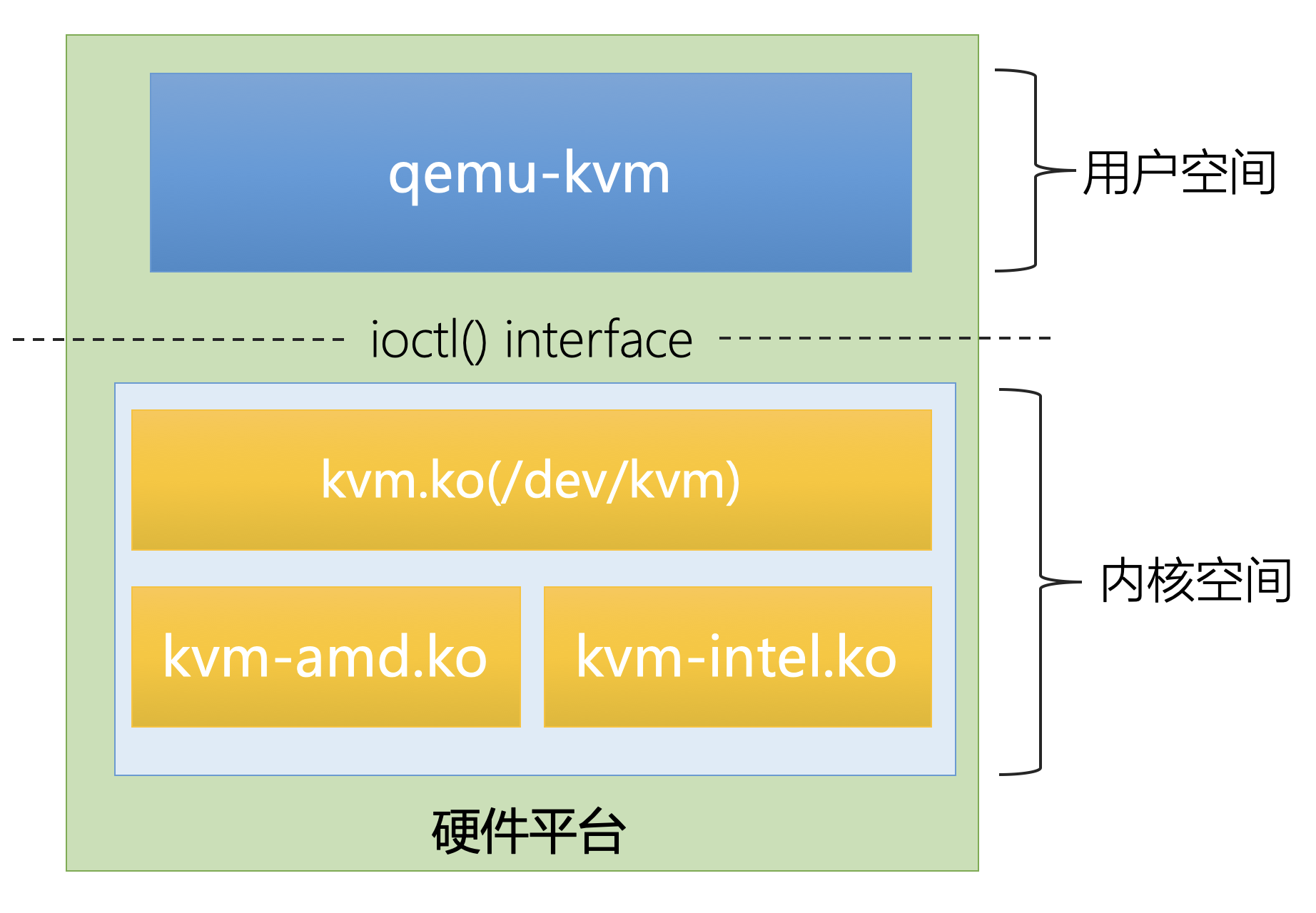
KVM 和 QEMU 有两种交互方式:通过设备文件/dev/kvm 和通过内存映射页面。QEMU 和 KVM之间的大块数据传递会使用内存映射页面。/dev/kvm是KVM暴露的主要API,它支持一系列ioctl接口,QEMU 使用这些接口和KVM交互。/dev/kvm API分为三个层次:
- System Level: 用于
KVM全局状态的维护,例如创建VM; - VM Level: 用于处理和特定
VM相关工作的 API,vCPU就是通过这个级别的API创建出来的; - vCPU Level: 这是最细粒度的API,用于和特定
vCPU的交互。QEMU会为每个vCPU分配一个专门的线程。
# CPU 虚拟化技术 VT-x
KVM和QEMU配合完美,但和CPU的特权级别在一起就遇到了麻烦。我们知道,hypervisor需要管理宿主机的CPU、内存、I/O设备等资源,因此它需要运行在ring 0级别才能执行这些高特权操作。然而运行在VM中的操作系统希望得到访问所有资源的权限,它并不知道自己运行在虚拟机中。因为同一时间只有一个内核可以运行在ring 0,Guest OS不得不被“挤”到了ring 1,这一级别不能满足内核的需求。怎么解决?
虽然我们可以使用软件的方式进行模拟,让hypervisor拦截应用发往ring 0的系统调用,再转发给Guest OS,但这么做会产生额外的性能损耗,而且方案复杂难以维护。Intel和AMD认识到了虚拟化的重要性,各自独立创建了X86架构的扩展指令集,分别称为 VT-x and AMD-V,从CPU层面支持虚拟化。
以Intel CPU为例,VT-x不仅增加了虚拟化相关的指令集,还将CPU的指令划分会两种模式:root 和 non-root。hypervisor运行在 root 模式,而VM运行在non-root模式。指令在non-root模式的运行速度和root模式几乎一样,除了不能执行一些涉及CPU全局状态切换的指令。
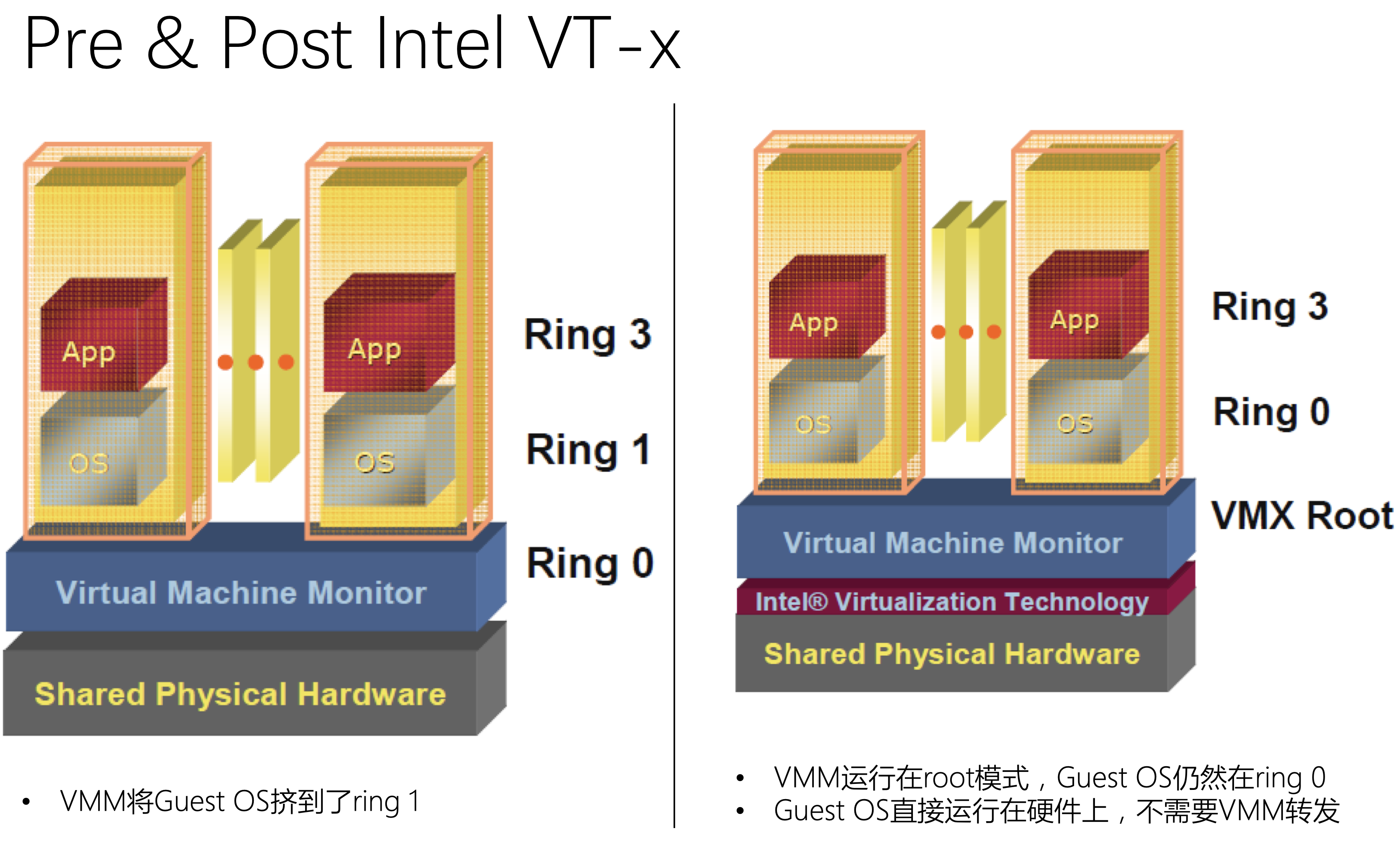
VMX(Virtual Machine Extensions)是增加到VT-x中的指令集,主要有四个指令:
- VMXON:在这个指令执行之前,CPU还没有
root和non-root的概念。VMXON执行后,CPU进入虚拟化模式。 - VMXOFF:
VMXON的相反操作,执行VMXOFF退出虚拟化模式。 - VMLAUNCH:创建一个
VM实例,然后进入non-root模式。 - VMRESUME:进入
non-root模式,恢复前面退出的VM实例。当VM试图执行一个在non-root禁止的指令,CPU立即切换到root模式,类似前面介绍的系统调用trap方式,这就是VM的退出。
这样,VT-x/KVM/QEMU 构成了今天应用最广泛的虚拟化技术栈。
有了上面的铺垫,终于要谈到容器技术了。
# 容器的本质
虽然虚拟化技术在灵活高效的使用硬件资源方面前进了一大步,但人们还觉得远远不够。特别是在机器使用量巨大的互联网公司。因为虚拟机一旦创建,为它分配的资源就相对固定,缺乏弹性,很难再提高机器的利用率。而且创建、销毁虚拟机也是相对“重”的操作。这时候容器技术出现了。我们知道,容器依赖的底层技术,Linux Namesapce和Cgroups都是最早由Google开发,提交进Linux内核的。
容器的本质就是一个进程,只不过对它进行了Linux Namesapce隔离,让它“看”不到外面的世界,用Cgroups限制了它能使用的资源,同时利用系统调用pivot_root或chroot切换了进程的根目录,把容器镜像挂载为根文件系统rootfs。rootfs中不仅有要运行的应用程序,还包含了应用的所有依赖库,以及操作系统的目录和文件。rootfs打包了应用运行的完整环境,这样就保证了在开发、测试、线上等多个场景的一致性。
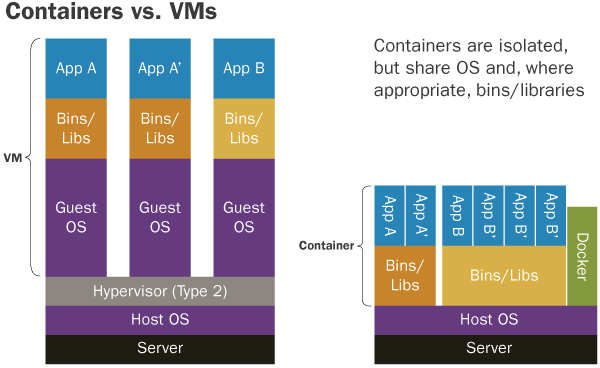
从上图可以看出,容器和虚拟机的最大区别就是,每个虚拟机都有独立的操作系统内核Guest OS,而容器只是一种特殊的进程,它们共享同一个操作系统内核。
看清了容器的本质,很多问题就容易理解。例如我们执行 docker exec 命令能够进入运行中的容器,好像登录进独立的虚拟机一样。实际上这只不过是利用系统调用setns,让当前进程进入到容器进程的Namesapce中,它就能“看到”容器内部的情况了。
由于容器就是进程,它的创建、销毁非常轻量,对资源的使用控制更加灵活,因此让Kubernetes这种容器编排和资源调度工具可以大显身手,通过合理的搭配,极大的提高了整个集群的资源利用率。
# 虚拟化容器技术
前面提到,运行在一个宿主机上的所有容器共享同一个操作系统内核,这种隔离级别存在着很大的潜在安全风险。因此在公有云的多租户场景下,还是需要先用虚拟机进行租户强隔离,然后用户在虚拟机上再使用容器+Kubernetes部署应用。
然而在Serverless的场景下,传统的先建虚拟机再创建容器的方式,在灵活性、执行效率方面难以满足需求。随着Serverless、FaaS(Function-as-a-Service)的兴起,各公有云厂商都将安全性容器作为了创新焦点。
一个很自然能想到的方案,是结合虚拟机的强隔离安全性+容器的轻量灵活性,这就是虚拟化容器项目 KataContainers。
OpenStack在2017年底发布的 KataContainers 项目,最初是由 Intel ClearContainer 和 Hyper runV 两个项目合并而产生的。在Kubernetes场景下,一个Pod对应于Kata Containers启动的一个轻量化虚拟机,Pod中的容器,就是运行在这个轻量级虚拟机里的进程。每个Pod都运行在独立的操作系统内核上,从而达到安全隔离的目的。
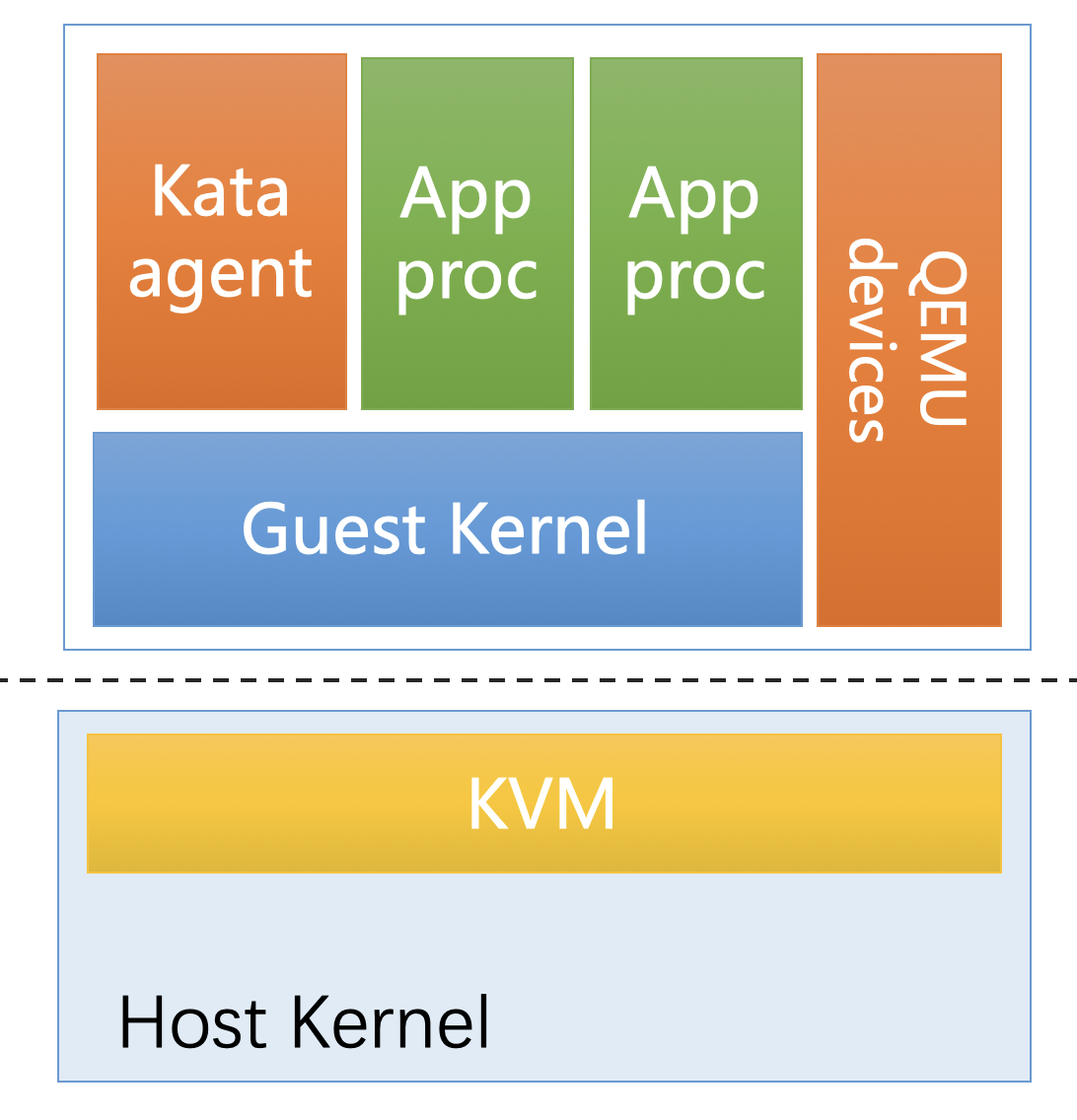
可以看出,KataContainers 依赖 KVM/QEMU技术栈。
amazon最近开源的Firecracker也是为了实现在 functions-based services 场景下,多租户安全隔离的容器。
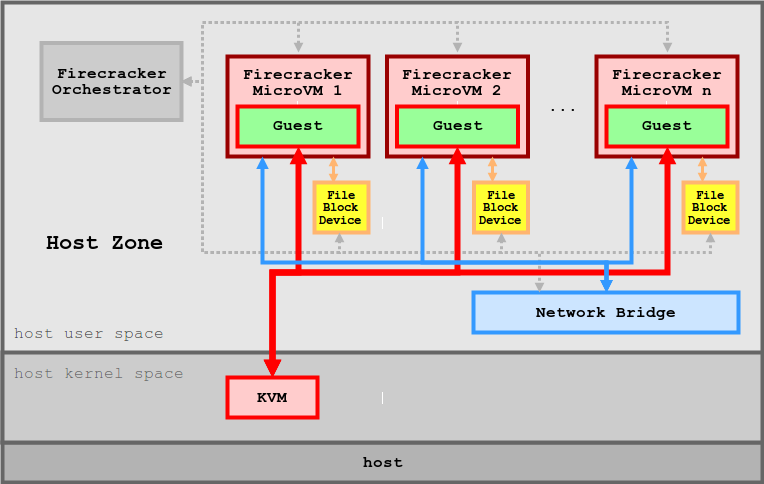
Firecracker同样依赖KVM,然后它没有用到QEMU,因为Firecracker本身就是QEMU的替代实现。Firecracker是一个比QEMU更轻量级的VMM,它只仿真了4个设备:virtio-net,virtio-block,serial console和一个按钮的键盘,仅仅用来停止microVM。理论上,KataContainers可以用Firecracker换掉它现在使用的QEMU,从而将 Firecracker整合进Kubernetes生态圈。
其实Google早就没有使用QEMU,而且对KVM进行了深度定制。我们可以从这篇介绍看出端倪:7 ways we harden our KVM hypervisor at Google Cloud: security in plaintext
Non-QEMU implementation: Google does not use QEMU, the user-space virtual machine monitor and hardware emulation. Instead, we wrote our own user-space virtual machine monitor that has the following security advantages over QEMU
…
# gVisor
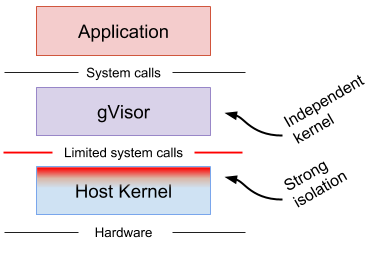
Google 开源的gVisor为了实现安全容器另辟蹊径,它用 Go 实现了一个运行在用户态的操作系统内核,作为容器运行的Guest Kernel,每个容器都依赖独立的操作系统内核,实现了容器间安全隔离的目的。
虽然 gVisor 今年才开源,但它已经在Google App Engine 和 Google Cloud Functions运行了多年。
gVisor作为运行应用的安全沙箱,扮演着Virtual kernel的角色。同时gVisor 包含了一个兼容Open Container Initiative (OCI) 的运行时runsc,因此可以用它替换掉 Docker 的 runc,整合进Kubernetes生态圈,为Kubernetes带来另一种安全容器的实现方案。
Kata Containers和gVisor的本质都是为容器提供一个独立的操作系统内核,避免容器共享宿主机的内核而产生安全风险。KataContainers使用了传统的虚拟化技术,gVisor则自己实现了一个运行在用户态、极小的内核。gVisor比KataContainers更加轻量级,根据这个分享的介绍,gVisor目前只实现了211个Linux系统调用,启动时间150ms,内存占用15MB。
gVisor实现原理,简单来说是模拟内核的行为,使用某种方式拦截应用发起的系统调用,经过gVisor的安全控制,代替容器进程向宿主机发起可控的系统调用。目前gVisor实现了两种拦截方式:
- 基于Ptrace 机制的拦截
- 使用
KVM来进行系统调用拦截。
因为gVisor基于拦截系统调用的实现原理,它并不适合系统调用密集的应用。
最后,对于像我这样没有读过Linux内核代码的后端程序员,gVisor是一个很好的窥探内核内部实现的窗口,又激起了我研究内核的兴趣。Twitter上看到有人和我有类似的看法:
希望下次能分享gVisor深入研究系列。保持好奇心,Stay hungry. Stay foolish.