
提到 Java 的垃圾回收(GC),很多开发者脑海中会立刻浮现出一个词:“Stop-The-World”,也就是我们常说的 STW。它意味着在那一刻,所有的应用线程都会被冻结,等待 GC 完成它的工作。这是 Java 应用的性能“痛点”,我们总希望它越短越好。
我们知道 STW 会暂停应用,但你是否想过一个更深层次的问题:JVM 究竟是如何做到让成千上万个正在高速运行的线程,能在同一时刻“安全地”停下来呢?
更进一步,是只有 GC 才会引发这种全局暂停吗?如果 Java 应用出现了一次意料之外的卡顿,但 GC 日志却显示一切正常,那“元凶”又会是谁呢?
这些问题的答案,都指向了 JVM 运行时中一个至关重要,但又很少有人了解的底层机制:Safepoint。
实际上,垃圾回收只是使用 Safepoint 机制的众多“客户”之一。Safepoint 本身是 JVM 的一个更为底层的通用设施,是所有需要进行全局性操作(比如代码反优化、线程转储等)时,都必须依赖的坚实地基。
接下来,就让我们一起揭开 Safepoint 的神秘面纱,看看它是什么、为什么需要它,以及它又是如何在底层运作,并悄无声息地影响着我们的应用程序。
# 什么是 Safepoint
我们知道,JVM 有时需要执行一些影响全局的操作,最典型的就是垃圾回收(Garbage Collection)。要安全地进行这些操作,一个基本前提就是让所有正在忙碌的线程都停下来,即“Stop-The-World”。
那么,JVM 可以在任意时刻,暂停一个正在运行的线程吗?答案是:不能。
原因在于一个核心概念:状态的可解析性(State Parsability)。
# JIT 优化带来的问题
为了追求极致的性能,JIT(Just-In-Time) 会将热点代码编译成本地机器码,并进行各种优化,比如:
- 寄存器分配:为了读写更快,一个 Java 的对象引用,可能不是在线程运行栈的内存中,而是被临时放到了 CPU 寄存器中。
- 指令重排:为了充分利用 CPU 流水线,实际执行的机器指令顺序可能和我们代码的逻辑顺序并不一致。
- 方法内联:一些方法可能被内联(inlining),导致其独立的栈帧结构直接消失。
这些优化极大地提升了运行速度,但也带来了一个“副作用”:如果在任意一个时刻暂停线程,JVM 会发现自己面对一个“混乱”的现场,它可能无法分清 CPU 寄存器里的某个值到底是一个整数,还是一个对象引用。这种状态,我们称之为不可解析的(unparsable)。
如果在这种“不确定”的状态下强行进行垃圾回收,后果是灾难性的。JVM 可能会把一个存活的对象当成垃圾回收掉,或者在移动对象后没能更新所有指向它的引用(包括那些藏在寄存器里的引用),最终导致程序崩溃。
# OopMap:JIT 为 JVM 运行时生成的“地图”
为了解决这个问题,JIT 编译器和 JVM 达成了一个的协议:JIT 在编译代码时,会为某些特定的指令位置额外生成一份元数据,这份元数据就像一张地图,它被称为 OopMap (Object Pointer Map)。
这张“地图“精确地记录了:“如果程序恰好在这个指令位置停下,那么它的栈和寄存器应该这样解读:RAX寄存器里的是一个对象引用,栈上-8偏移量处是一个整数,-16偏移量处又是一个对象引用……”
有了这份地图,垃圾回收器就能准确地找出当前线程中所有的根对象(GC Roots),从而安全地进行后续的存活对象分析。
为了解决这个问题,JIT 编译器为 JVM 准备好了一份地图(OopMap - Object Pointer Map),这份地图精确地记录了在当前这个点,哪些寄存器、哪些栈位置存放的是对象引用。有了这张地图,垃圾回收器(GC)就能准确地找出所有的根对象(GC Roots),从而安全地进行存活对象分析。
但是,为每一条机器指令都生成这样一张“地图”的成本太高了,会消耗大量内存并拖慢编译过程。因此,JIT 只会在某些特定的、易于管理的位置生成和保存“地图”。
这些带有正确“地图”信息,能够让 JVM 安全解析线程状态的特定位置,就是安全点(Safepoint)。
# Safepoint:一个协作式的“约定地点”
现在我们可以给 安全点(Safepoint) 一个更清晰的定义:
Safepoint 是代码中预先定义好的特定位置,当一个线程执行到这些位置时,它的底层执行状态(寄存器、栈)是确定的,能够被 JVM 准确的解析,并可以被 JVM 安全地检查和修改。
因此,当 JVM 需要暂停所有线程时(例如进行 GC),它不会简单粗暴的直接中断它们的执行,而是会设置一个全局标志,然后等待所有线程主动运行到离它们最近的一个 Safepoint,在那里检查到这个标志后,自行决定暂停。
这就是 Safepoint 机制的核心:它采用 协作式(Cooperative) 的方式工作。JVM 无法强迫线程停下,只能等待线程“自觉”地走到一个双方约定好的、可以安全“交接”的地方。这种机制,保证了所有全局操作的绝对安全和正确。
# Safepoint 的应用场景
提到“Stop-The-World”,大部分开发者首先想到的就是垃圾回收。GC 的许多关键阶段,都需要在一个全局的 Safepoint 中进行,可以安全的进行对象的标记和清理。
但是,如果我们将 Safepoint 仅仅与 GC 划上等号,那就大大低估了它的重要性。
实际上,Safepoint 是 JVM 的一个基础性平台机制。任何需要安全地检查或修改所有线程共享数据(如堆、类元数据、线程栈等)的重量级操作,都必须依赖它来创造一个安全确定的执行环境。GC 只是这个平台上最“知名”的客户而已。
除了 GC,还有一些常见的 VM 操作,同样需要在全局 Safepoint 中执行:
-
代码反优化 (Deoptimization):当 JIT 编译后的代码因为某些原因(如分支预测失败、加载了未被预期的子类等)需要回退到解释执行状态时,JVM 需要暂停线程,修改其栈帧,这个过程必须在 Safepoint 中进行。
-
类的重定义与热部署 (Class Redefinition):像我们在 IDE 中热更新代码,或者使用某些动态诊断工具时,JVM 需要替换掉已加载的类。这个操作会涉及修改类的元数据和可能存在的实例,显然也需要所有线程暂停。
-
线程堆栈转储 (Thread Dump):当我们使用
jstack或其他工具来获取所有线程的堆栈快照时,为了得到一个准确、一致的视图,JVM 会触发一次 Safepoint。 -
堆转储 (Heap Dump):与线程转储类似,生成堆快照也需要在一个静态的内存视图下进行。
-
偏向锁批量撤销 (Bulk Revocation of Biased Locks):当某个类的偏向锁被大量撤销时,JVM 需要遍历所有线程栈和堆,找到并修改相关的锁记录。
-
其他 JVMTI 操作:许多通过 JVMTI(JVM Tool Interface)提供的调试和监控功能,例如强制修改变量值等,也依赖 Safepoint 来保证操作的原子性和安全性。
因此,下一次当你的应用出现卡顿,而 GC 日志却“清白无辜”时,不妨思考一下,是否是上述这些原因之一,触发了一次意料之外的 Safepoint 停顿。
# Safepoint 的工作机制
我们已经知道,JVM 无法在任意时刻强行暂停线程,而是需要线程的“协作”。那么,所有线程的“集体暂停”,是如何发生的呢?
# 协作式轮询机制
整个机制的核心是一种协作式轮询(Cooperative Polling)。它的工作流程非常直观:
- 当 JVM 需要所有线程进入 Safepoint 时,它会设置一个全局的“请暂停”标志。
- 每个正在运行的应用线程,在执行自己代码的同时,会周期性地检查这个全局标志。
- 一旦某个线程发现这个全局标志被设置,它立即在这个安全的位置停下,并自行进入阻塞状态。
- JVM 会一直等待,直到所有的应用线程都到达了各自的 Safepoint 并进入阻塞状态。
- 此时,JVM 可以安全地进行它的全局操作(如垃圾回收、代码去优化等),因为它知道所有线程都处于可解析的稳定状态。
- 全局操作完成后,JVM 会清除那个全局的“请暂停”标志,并唤醒所有正在阻塞的线程。
- 线程们被唤醒后,它们从之前暂停的 Safepoint 处,继续执行自己的代码。
# 轮询点的位置
一个很自然的问题是:线程在哪里进行轮询检查呢?
如果检查得太频繁,比如每条指令后都检查,那无疑会带来巨大的性能开销。如果检查得太少,又可能导致线程长时间无法响应暂停请求。因此,JIT 编译器采取了一种折衷策略,在一些关键位置插入轮询指令,这些位置被称为轮询点(Poll Locations):
- 方法的返回处:当一个方法即将返回给调用者之前。
- 循环的回边(Loop Back-edges):在一个循环即将进入下一次迭代之前。
值得注意的是,为了避免因编译器优化(比如将多个小循环合并成一个大循环)而导致线程长时间“失联”,现代的 JDK 倾向于在所有循环的回边都插入轮询点,这大大降低了线程无法及时响应 Safepoint 的风险。
如果你对汇编代码感兴趣,可以参考我以前的文章使用 PrintAssembly 查看 JIT 编译后的汇编代码,为 JDK 安装配置好准备 hsdis 插件,然后使用类似下面的命令行参数运行应用,查看你指定代码的 JIT 反汇编:
|
|
随着程序的运行,你可以看到热点代码 C1、C2 编译结果的反汇编输出。输出的反汇编代码包含了丰富的注释,其中的注释 {poll} 和 {poll_return} 就表明是安全点轮询 (Safepoint Poll)。
|
|
# 核心性能指标:到达安全点的时间 (Time-To-Safepoint, TTSP)
现在,我们来到了 Safepoint 机制中对性能影响最大,也很容易被忽视的一环。
想象一下,JVM 设置了全局的“请暂停”标志,此刻:
- 线程 A 可能正好执行完一次循环,它立刻看到了标志,并马上在 Safepoint 处暂停了。
- 线程 B 可能正在执行一段长计算的中间部分,它需要再运行多条指令才能到达下一个循环的末尾,也就是下一个轮询点。
JVM 的全局操作(如 GC)必须等到所有线程都暂停后才能开始。这意味着,即使线程 A 已经早早地“就位”,它也必须原地等待,直到最慢的线程 B 姗姗来迟。
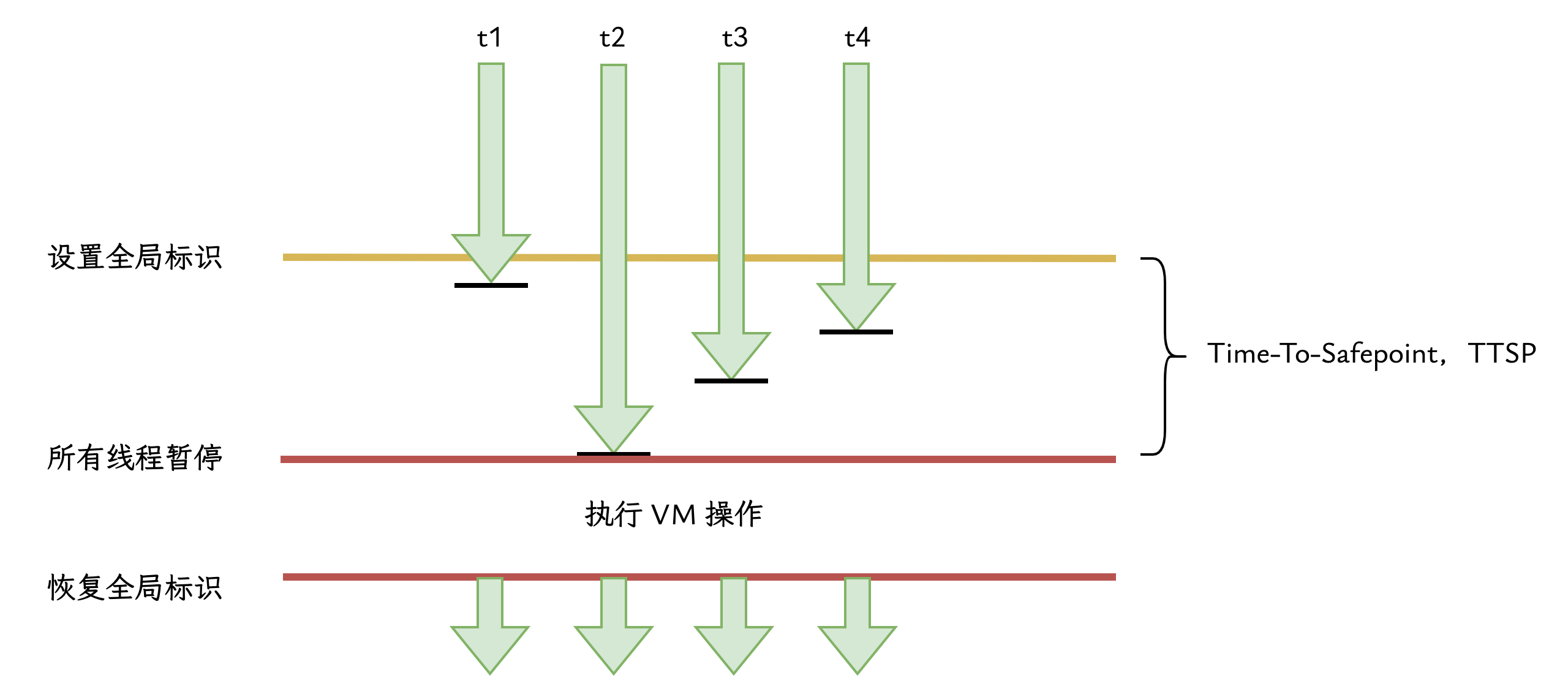
从 JVM 发起暂停请求,到最后一个线程终于到达 Safepoint 并暂停,这段等待时间,被称为 “到达安全点的时间”(Time-To-Safepoint,简称 TTSP)。
总停顿时间 ≈ 到达安全点的时间 (TTSP) + 安全点内VM操作的耗时
这个公式表明,我们通过 GC 日志看到的停顿时间,仅仅是公式的后半部分。而同样会冻结应用的 TTSP,却隐藏在幕后。在某些极端情况下,一个行为异常的线程导致的超长 TTSP,甚至可能超过 GC 本身的时间,成为应用卡顿的真正元凶。后面我会介绍使用 -Xlog:safepoint 参数,查看每次暂停的 TTSP。
# OpenJDK 底层实现揭秘
理解了 Safepoint 的“是什么”和“为什么”,我们现在深入其内部,看看在 OpenJDK 中,这一切是如何通过代码实现的。
# VMThread 与 VM_Operation
在 JVM 内部,存在一个特殊的系统级线程,名为 VMThread。它不执行任何 Java 应用代码,其核心职责是管理和执行需要全局协调的内部任务。它是一个单一的、高优先级的后台线程,核心使命是处理那些需要全局一致性的、重量级的内部任务。这些任务如果由普通应用线程来执行,可能会引发复杂的竞态条件和死锁问题。因此,将它们集中交由一个专职的 VMThread 来处理,是 JVM 内部的一种设计模式。
当 JVM 的某个子系统(比如 GC、JIT 编译器、代码热更新模块等)需要执行一个全局操作时,它不会直接动手,而是把这个操作封装成一个对象,这个对象就是 VM_Operation。VM_Operation 是一个任务的抽象,它清晰地定义了需要执行什么操作(doit() 方法)以及这个操作是否需要在 Safepoint 中进行(evaluate_at_safepoint() 方法)。
这种设计的好处在于解耦:任务的“请求方”和“执行方”被分开了。请求方只需创建一个 VM_Operation 并将其提交到一个共享的任务队列 VMOperationQueue 中,而无需关心复杂的线程同步和暂停逻辑。
我们可以在 vmOperation.hpp 中,查看目前 JVM 支持的所有 VM_Operation 列表:
|
|
从上面的列表中可以看到,各 GC 算法需要在 Safepoint 交由 VMThread 执行的 VM 操作。当然也包含一些非 GC 的其他 VM 操作,如 ThreadDump。
# Safepoint 整体流程
有了 VMThread 和 VM_Operation 这两个基本构件,Safepoint 的整体执行流程就变得非常清晰了。它是一个标准化的、由 VMThread 主导的调度过程。
-
提交任务
当一个需要 Safepoint 的
VM_Operation被创建并提交到VMOperationQueue后,它就进入了等待处理的状态。 -
调度与发起
VMThread 在其主循环中,从队列里取出这个
VM_Operation。在确认该任务需要 Safepoint 后,它便调用SafepointSynchronize::begin(),正式启动了将所有线程带入 Safepoint 的同步过程。 -
武装与轮询
begin()方法会设置一个全局的 Safepoint 状态标志,并遍历所有存活的 JavaThread 实例,修改它们各自线程本地的轮询状态。这个过程被称为 “武装”(Arming)。此后,每个正在运行的线程在执行到代码中的 轮询点(Poll Location) 时,就会检测到这个状态改变。 -
阻塞与同步
一旦检测到暂停请求,线程会主动执行
SafepointSynchronize::block()方法,使自身进入阻塞状态,并在一个全局的屏障(WaitBarrier)上等待。VMThread 则会持续检查所有线程的状态,直到确认所有线程都已暂停。这个等待所有线程完成同步的耗时,就是 TTSP(Time-To-Safepoint)。 -
执行操作
一旦确认所有线程都已同步,JVM 就进入了一个全局静止状态。此时,VMThread 才安全地调用
VM_Operation对象的核心doit()方法,执行实际的任务逻辑(例如,GC 扫描)。 -
恢复执行
操作完成后,VMThread 调用
SafepointSynchronize::end()方法。该方法负责重置全局状态,解除对各线程轮询状态的“武装”,并最终通过WaitBarrier唤醒所有被阻塞的 Java 线程,使其恢复正常执行。
这个流程确保了所有全局操作都在一个绝对安全、一致的环境中进行,是 JVM 稳定运行的基石。在接下来的部分,我们将深入探讨第 3 步中的“轮询”是如何在不同执行模式下被高效实现的。
# JIT 代码的轮询:利用页保护(Page Protection)
对于经过 JIT 编译的高度优化的代码,性能是第一要务。如果在循环中频繁地使用 if-else 条件分支来检查 Safepoint 标志,会对 CPU 的指令流水线造成干扰,带来不可忽视的性能损失。
为了实现一个近乎“零开销”的轮询,OpenJDK 的工程师们采用了一个极为巧妙的方案,它利用了现代操作系统和硬件提供的一项功能:页保护(Page Protection)。
# 什么是页保护机制
页保护是现代操作系统与 CPU 硬件协同提供的一项内存管理基础功能。操作系统不直接管理单个字节,而是以 页(Page) 为单位(通常是 4KB)来管理内存。
这个机制的核心是虚拟内存系统。程序中使用的地址并非真实的物理内存地址,而是虚拟地址。操作系统通过 页表(Page Table) 来维护虚拟地址到物理地址的映射关系。当程序访问一个虚拟地址时,CPU 内的 内存管理单元(MMU) 会查询页表,完成地址转换。
关键在于,页表的每一项不仅记录了映射关系,还附带了一组保护标志(Protection Flags),用以规定该内存页的访问权限。常见的权限包括:
PROT_READ:允许读取。PROT_WRITE:允许写入。PROT_EXEC:允许执行代码。PROT_NONE:不允许任何形式的访问。
当程序访问一个内存页时,MMU 会首先检查其权限。如果访问合法,操作顺利完成。但如果程序试图读、写或执行一个被设置为 PROT_NONE 的页,MMU 会立即识别出这是非法操作,并触发一个硬件层面的异常。这个异常会使 CPU 陷入(trap) 操作系统内核。内核的异常处理器随即接管,分析异常原因,并向引发问题的进程发送一个特定的信号(Signal),在 Linux 上通常是 SIGSEGV(段错误)。
简单来说,页保护机制就像给每个内存页上了一把锁。如果你有正确的权限,就能进入;如果没有,就会引发硬件异常,由操作系统内核接管,并向你发送SIGSEGV 信号。
# OpenJDK 如何利用这一机制
Safepoint 轮询机制面临的挑战是:检查操作必须在性能关键路径上(例如循环中),所以它必须极度高效。如果每次都用 if (should_stop) { ... } 这样的条件分支来检查,会对 CPU 的指令流水线造成干扰,影响性能。
OpenJDK 的实现另辟蹊径,将软件层面的轮询检查转换为了一个硬件层面的事件。我们再来看 OpenJDK 的实现:
-
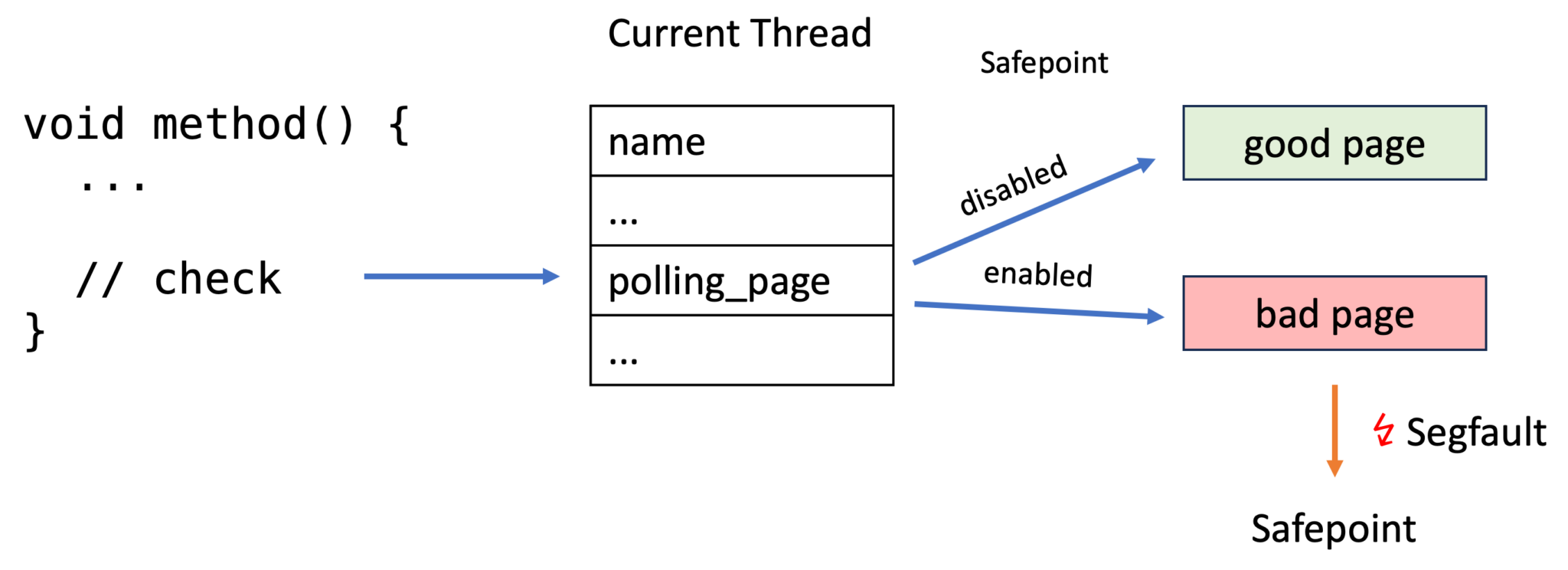
初始化:创建特殊的内存页
在 JVM 启动时,它会通过系统调用分配一个特殊的内存页,我们称之为轮询页(Polling Page)。这个页被设置为没有任何访问权限(
PROT_NONE)。1 2 3 4 5 6 7 8 9// 源码片段中的逻辑 (SafepointMechanism.cpp) // 分配内存,一部分作为 bad_page,一部分作为 good_page char* polling_page = os::reserve_memory(allocation_size, !ExecMem, mtSafepoint); char* bad_page = polling_page; char* good_page = polling_page + page_size; os::protect_memory(bad_page, page_size, os::MEM_PROT_NONE); // 关键!设置为无权限 os::protect_memory(good_page, page_size, os::MEM_PROT_READ); // 设置为可读从上面的代码中,可以看出,JVM 会分配两个相邻的页,一个无权限的
bad_page和一个有读权限的good_page,通过切换线程本地指针来指向其中一个。 -
JIT 编译:插入轮询指令
当 JIT 编译热点代码时,它会在需要进行 Safepoint 检查的地方(如循环的回边、方法返回前)插入一条非常简单的内存读取指令。
在 x86 汇编中,这条指令看起来像这样:
1test dword ptr [r10], eax; {poll}这条指令的作用是尝试从某个固定的虚拟地址(轮询页的地址)读取数据。
-
正常执行(快速路径)
在绝大多数时间里,JVM 并不需要线程暂停。
此时,虽然 JIT 编译的代码中包含了内存读取指令,但
test指令要访问的内存地址是一个合法的、可读的普通内存地址(good_page)。因此,test指令每次都能成功执行,速度极快,几乎不产生任何性能开销,也不会引起分支预测失败。这是 Safepoint 机制性能如此之高的关键。 -
发起 Safepoint(慢速路径)
当
VMThread决定发起一次全局 Safepoint 时,它会执行一个关键动作:将所有线程的轮询指针,都修改为指向那个被保护的、权限为PROT_NONE的轮询页地址(bad_page)。 -
触发与处理
此后,任何一个正在执行 JIT 代码的线程,当它再次运行到那条
test内存读取指令时,就会试图访问一个PROT_NONE的地址。MMU 立刻捕获到这次非法访问,触发硬件异常,使系统陷入内核,并最终由操作系统向 JVM 进程发送SIGSEGV信号。JVM 内部预先注册了一个自定义的
SIGSEGV信号处理器。当处理器被调用时,它会检查导致段错误的内存地址。如果发现地址正是那个特殊的轮询页,它便知道这并非程序缺陷,而是一个预期的 Safepoint 触发事件。于是,它会引导当前线程执行SafepointSynchronize::block()进入阻塞状态,等待 Safepoint 结束。
通过这种方式,OpenJDK 将一个频繁的软件检查,转换成了一个在绝大多数情况下无开销的硬件操作,只在需要时才通过一个可控的硬件异常进入处理流程。
# 其他场景下的 Safepoint 处理
页保护机制是为高性能 JIT 代码量身定制的方案。对于仍在解释器中运行的代码,或是已进入 JNI 的线程,JVM 采用了不同的处理方式。
-
解释器代码 (Interpreted Code)
解释器的工作模式是逐条地翻译和执行字节码,其性能无法与 JIT 编译后的代码相比。因此,它采用了更直接的轮询方式。
当 Safepoint 被“武装”时,解释器会切换到一个备用的派发表(Dispatch Table),这个备用表中的字节码实现,在执行循环跳转等指令时,会额外包含一条直接检查线程本地 Safepoint 标志位的指令。这种方式避免了复杂的信号处理,实现简单明了。
-
原生代码 (Native Code / JNI)
当一个 Java 线程进入 JNI 调用,执行原生 C/C++ 代码时,它已经脱离了 JVM 的直接控制,自然也无法进行轮询。此时,JVM 会将这个线程标记为正在执行原生代码(_thread_in_native)。从 JVM 的视角看,这个线程的 Java 栈是固定的、安全的。
当这个线程执行完原生代码,准备返回 Java 世界时,在过渡阶段,它必须检查全局的 Safepoint 标志。如果此时 JVM 正处于一个全局 Safepoint 中,该线程会被暂停在返回的关口,直到 Safepoint 结束,才能安全地继续执行 Java 代码。
-
已阻塞的线程 (Blocked Threads)
这是最简单的一种情况。对于那些已经因为锁竞争、执行
Object.wait()、Thread.sleep()或阻塞式 I/O 而处于阻塞状态的线程,它们本身就已经“静止”了,不会对 JVM 的全局操作构成威胁。因此,当 VMThread 在进行同步时,一旦检测到某个线程处于
_thread_blocked状态,就会直接将其视为已完成同步,无需任何额外的操作。这些线程对 TTSP 的贡献时间为零。
至此,OpenJDK 通过为不同执行模式量身定制的策略,构建了一套完整而高效的 Safepoint 协作机制。
# 实战:监控与分析安全点
了解了 Safepoint 的工作原理后,我们最关心的问题是:如何知道我自己的应用程序中 Safepoint 的表现如何?它是否是导致我的应用卡顿的元凶?
幸运的是,OpenJDK 提供了一个强大的参数,让我们能清晰地看到每一次 Safepoint 操作的细节。
#
-Xlog:safepoint 参数
要开启 Safepoint 日志,你需要在启动 JVM 时添加 -Xlog 参数,并指定 safepoint 标签,例如:
|
|
这个配置会 Safepoint 日志输出到 safepoint.log 文件中。在 JDK 9 之前,可以使用 -XX:+PrintSafepoints 和 -XX:+PrintGCApplicationStoppedTime 这两个参数来获取类似的信息。
# 日志解读
开启日志后,你会看到类似下面这样的输出。我们来逐列解读其中的关键信息:
|
|
让我们以第一条日志为例,分解它的含义:
-
[5.745s]: 时间戳。表示从 JVM 启动到此次 Safepoint 操作开始的时间点。 -
Safepoint "G1CollectForAllocation": 触发原因。这是最重要的信息之一,它告诉我们这次全局暂停是由什么事件引起的。这里的G1CollectForAllocation意味着 G1 垃圾收集器因为堆内存分配请求无法满足而触发了一次 Young GC。在第二条日志中,原因则是ThreadDump,说明是外部工具请求了线程堆栈转储。 -
Time since last: 21216960 ns: 距离上次安全点的间隔。表示从上一个 Safepoint 结束到本次开始,应用程序自由运行的时间(约 21.2 毫秒)。这个值反映了 Safepoint 的发生频率。 -
Reaching safepoint: 23275 ns: 到达安全点耗时。这就是我们反复强调的 TTSP。这里是约 23.3 微秒,一个非常健康的值。它表示从 JVM 发起请求到所有线程都暂停,总共花了多长时间。 -
At safepoint: 3836938 ns: 在安全点内执行操作的耗时。这是真正的“Stop-The-World”时长,即 VMThread 执行其核心任务所花的时间。这里是约 3.8 毫秒。 -
Total: 3900312 ns: 总停顿时间。约等于Reaching safepoint+At safepoint的总和。这是应用线程从被请求暂停到最终被唤醒所经历的全部时间。
# 如何定位问题
通过分析这份日志,我们可以清晰地诊断出应用的停顿模式:
-
停顿的元凶是谁?
观察
Safepoint "Cause"字段。如果大部分停顿都由G1CollectForAllocation或类似 GC 原因引起,说明性能瓶颈在于对象分配速率过高或堆内存不足。如果看到很多Deoptimize或RevokeBias,则可能需要关注 JIT 编译或锁竞争的问题。 -
是 TTSP 过长,还是 VM 操作本身耗时?
这是分析的关键。对比
Reaching safepoint和At safepoint这两个值。-
如果
At safepoint很大(通常是毫秒级别),说明是 VM 操作本身很耗时。比如 GC 耗时长,就应该去调优 GC 参数或分析内存使用。 -
如果
Reaching safepoint很大(比如也达到了毫秒级别),这通常是一个更危险的信号,说明有线程花了很长时间才响应暂停请求。此时,你应该去检查代码中是否存在没有 Safepoint 轮询点的长计算,或者是否存在严重的 CPU 资源争抢。
-
以文章开头提供的日志为例,我们可以看到绝大多数停顿都是由 GC (G1CollectForAllocation, G1PauseRemark 等) 引起的,并且 At safepoint 时间远大于 Reaching safepoint 时间。这清晰地表明,该应用的停顿瓶颈在于 GC 操作本身,而不是 TTSP。
掌握了 Safepoint 日志的分析方法,你就拥有了一把强大的武器,能够更全面、更深入地诊断和优化 JVM 的停顿问题。
# 总结
希望通过本文的介绍,你能够建立起关于 Safepoint 的几个核心认知:
-
Safepoint 是所有 STW 停顿的基础。我们常说的 GC STW,其本质就是一次全局 Safepoint 操作。但 GC 只是触发 Safepoint 的众多“客户”之一,代码反优化、线程转储等多种 VM 操作同样依赖它。
-
这是一种“协作”,而非“命令”。JVM 无法在任意时刻强行中断一个正在高速运行的线程。它必须依赖线程主动在预设的轮询点检查并自行暂停。这种协作式机制,是保证所有全局操作安全、正确的前提。
-
停顿时间由两部分构成。一次完整的 Safepoint 停顿,包含了所有线程到达 Safepoint 的时间(TTSP)和在 Safepoint 内执行 VM 操作的时间。仅仅关注 GC 日志里的操作耗时是不够的,被忽略的 TTSP 常常是导致应用卡顿的“隐形杀手”。
-
高效的实现源于对底层的深刻理解。OpenJDK 通过巧妙地利用页保护和信号处理机制,为 JIT 编译代码实现了近乎零开销的轮询,这充分展现了现代虚拟机在性能工程上的智慧。
最终,理解 Safepoint 并不只是为了满足技术上的好奇心。它为我们提供了一个全新的、更底层的视角来审视应用的性能问题。下一次,当你面对一个棘手的延迟或性能抖动问题,在深入分析业务逻辑和 GC 日志之外,不妨也加上 -Xlog:safepoint,看一看那些隐藏在幕后的“集体暂停”,或许,问题的答案就藏在其中。