刚接触Kubernetes时很容易被它繁多的概念(POD,Service,Deployment …)以及比较复杂的部署架构搞晕,本文希望能通过一个简单的例子,讲解Kubernetes最基本的工作原理。
Kubernetes本质上是为用户提供了一个容器编排工具,可以管理和调度用户提交的作业。用户在 YAML 配置文件中描述应用所需的环境配置、参数等信息,以及应用期待平台提供的服务(负载均衡,水平扩展等),然后将 YAML 提交,Kubernetes会按照用户的要求,在集群上将应用运行起来。在遇到异常情况,或用户的主动调整时,Kubernetes 将始终保持应用实际的运行状态,符合用户的期待状态。
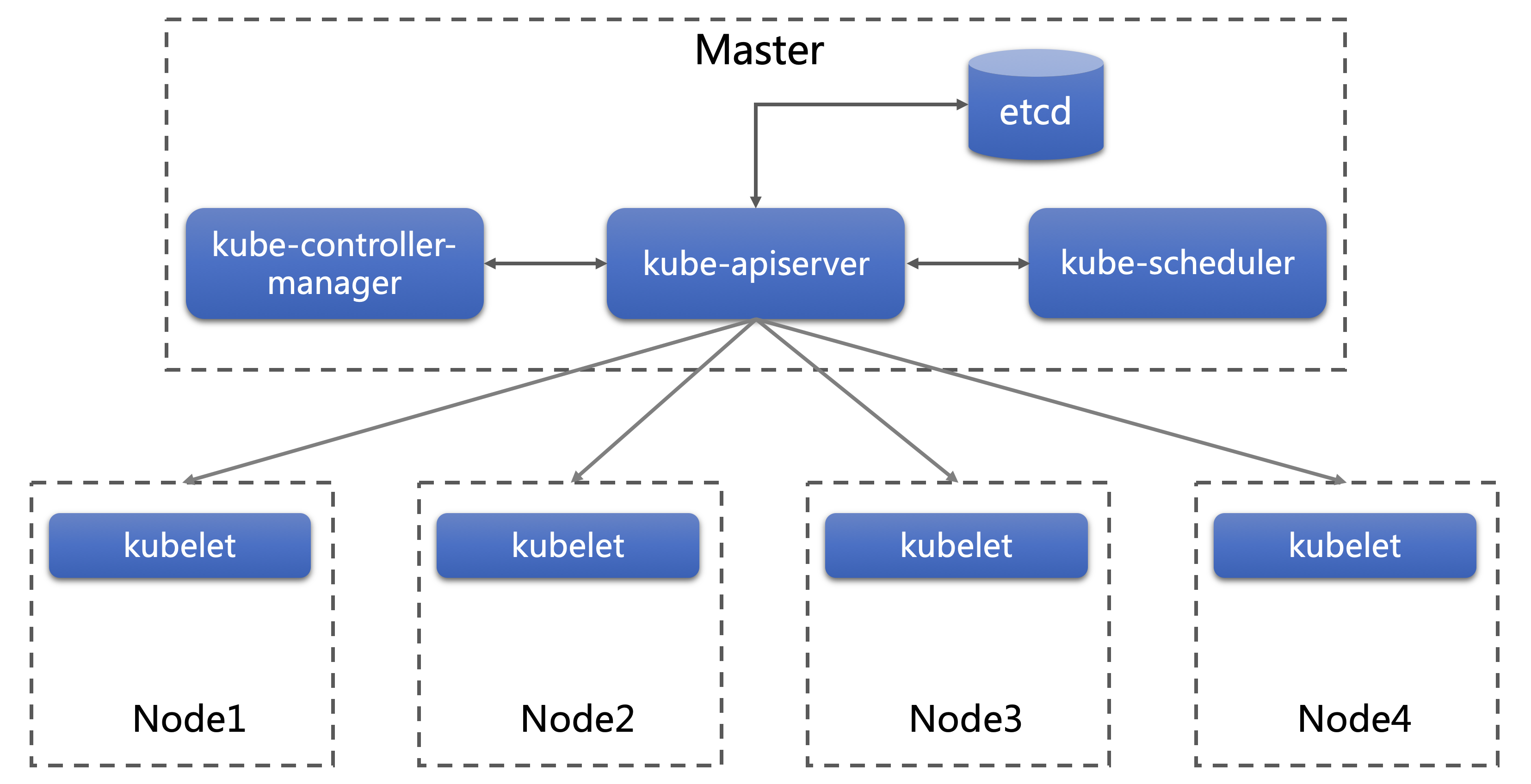
Kubernetes 是由 Master 和 Node 两种节点组成。Master由3个独立的组件组成:
- 负责 API 服务的
kube-apiserver - 负责容器编排的
kube-controller-manager - 负责调度的
kube-scheduler
Kubernetes 集群的所有状态信息都存储在 etcd,其他组件对 etcd 的访问,必须通过 kube-apiserver。
Kubelet 运行在所有节点上,它通过容器运行时(例如Docker),让应用真正的在节点上运行起来。
下面通过一个简单的例子,描述 Kubernetes 的各个组件,是如何协作完成工作的。
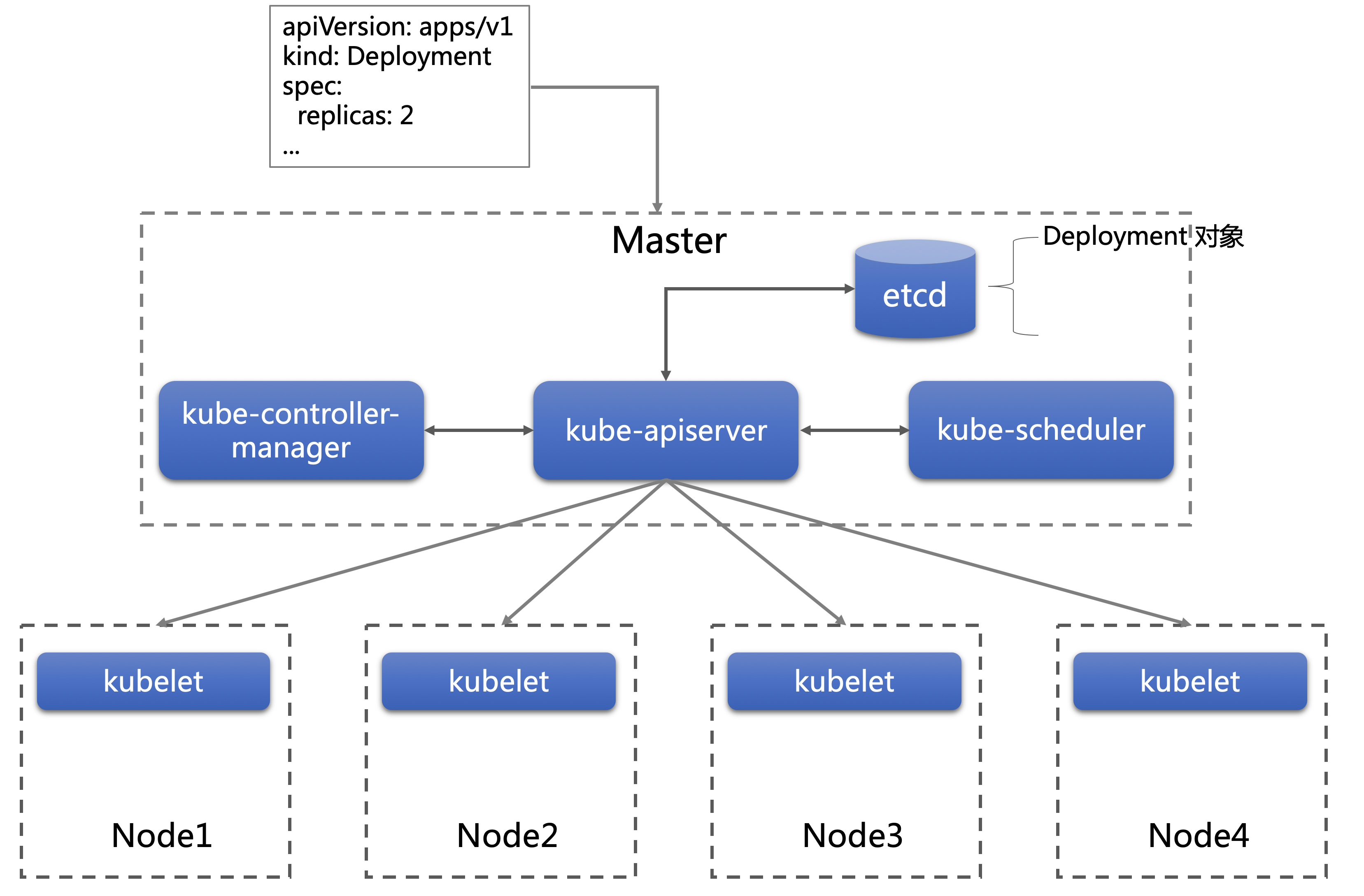
用户将 YAML 提交给 kube-apiserver,YAML 经过校验后转换为 API 对象,存储在 etcd 中。
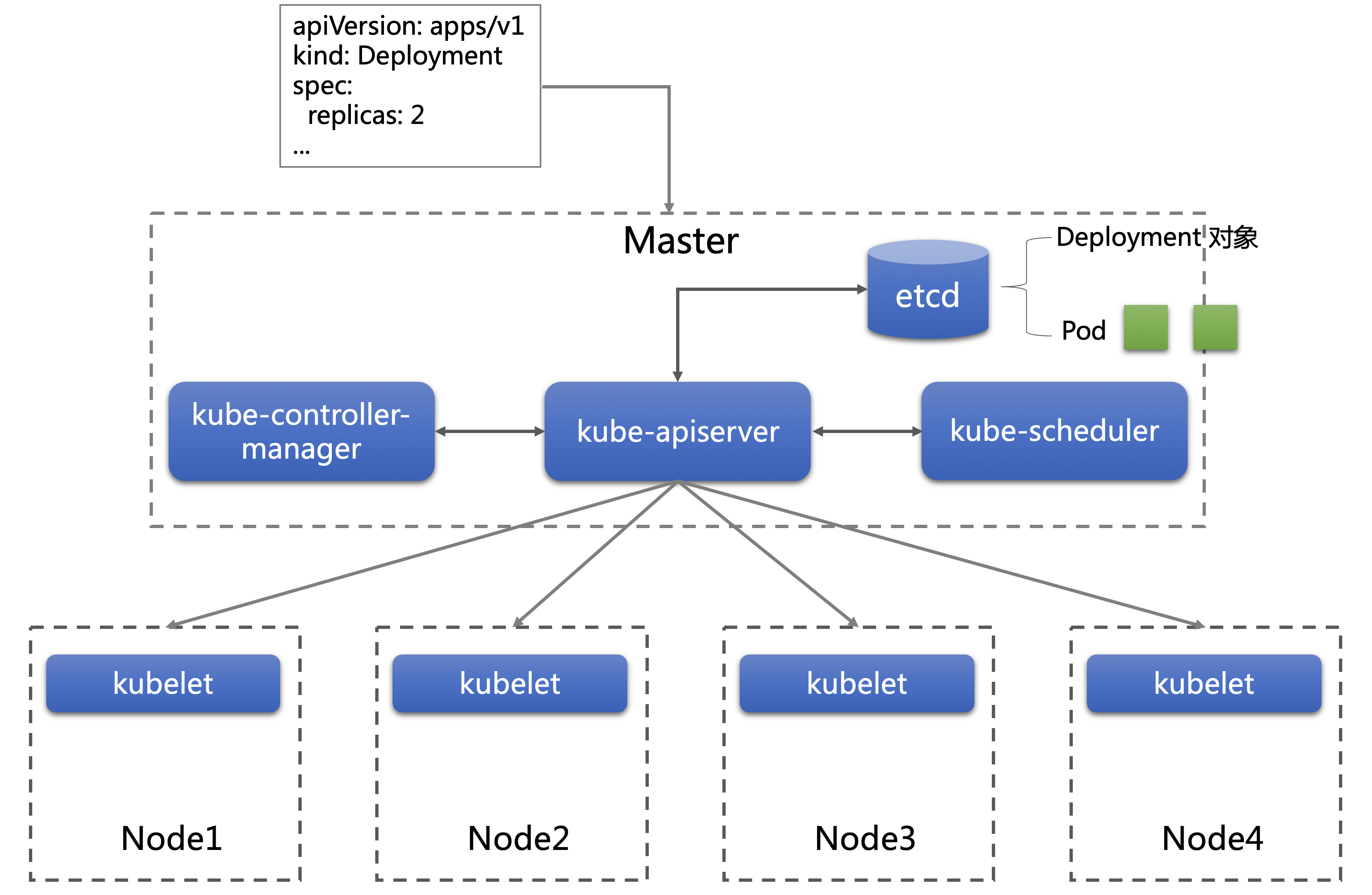
kube-controller-manager 是负责编排的组件,当它发现有新提交的应用,会根据配置的要求生成对应的 Pod 对象。Pod 是 Kubernetes 调度管理的最小单元,可以简单的认为,Pod 就是一个虚拟机,其中运行着关系紧密的进程,共同组成用户的应用。例如Web应用进程和日志收集agent,可以包含在一个Pod中。Pod 对象也存储在 etcd 中。本例子中用户定义 replicas 为2,也就是用户期待有两个 Pod 实例。
其实kube-controller-manager 内部一直在做循环检查,只要发现有应用没有对应的 Pod,或者 Pod 的数量不满足用户的期望,它都会进行适当的调整,创建或删除Pod 对象。
kube-scheduler 负责 Pod 的调度。kube-scheduler 发现有新的 Pod 出现,它会按照调度算法,为每个 Pod 寻找一个最合适的节点(Node)。kube-scheduler 对一个 Pod 的调度成功,实际上就是在 Pod 对象上记录了调度结果的节点名称。注意,Pod 调度成功,只是在 Pod 上标记了节点的名字,Pod 是否真正在节点上运行,就不是kube-scheduler的责任了。
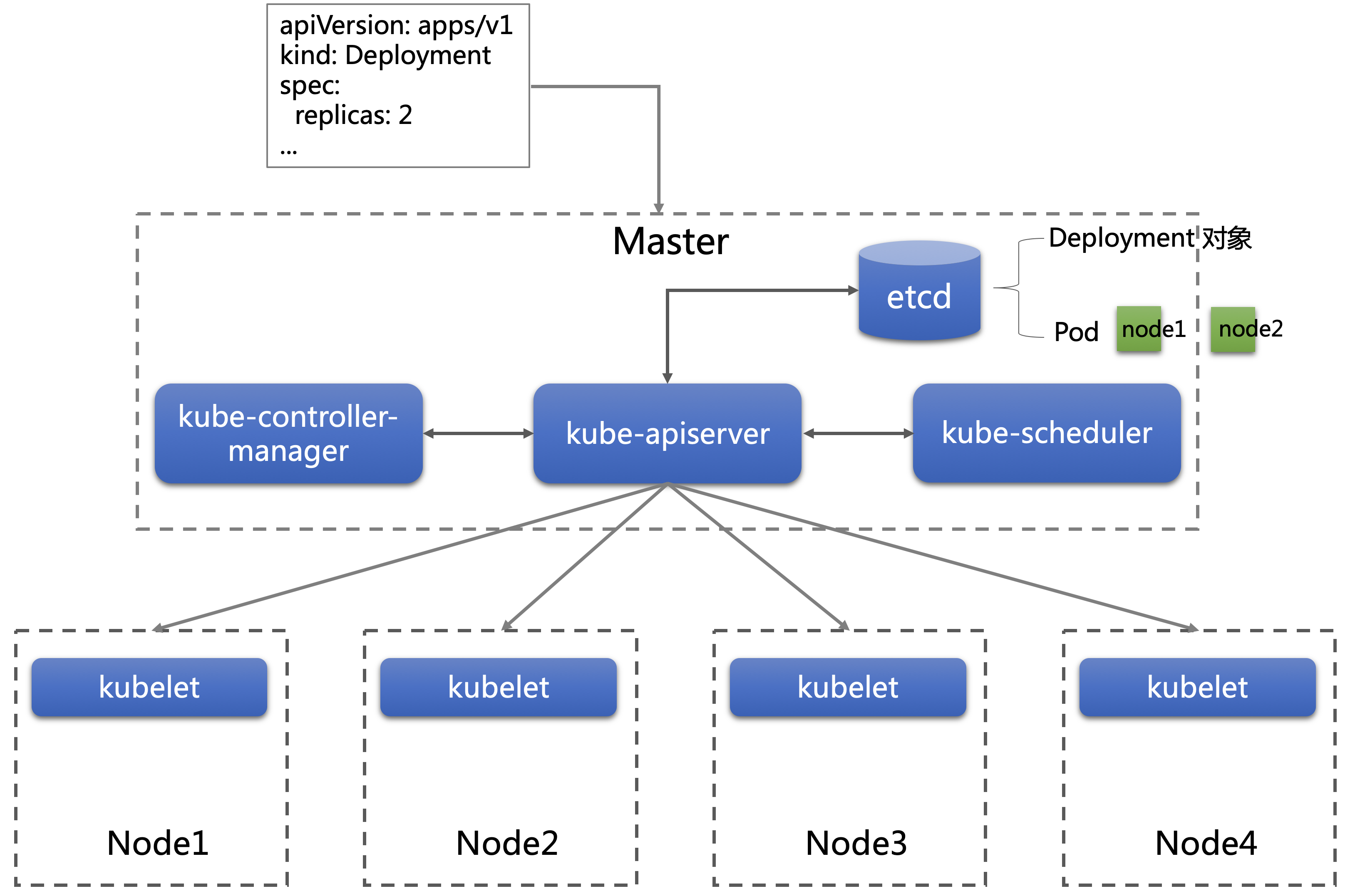
Kubelet 运行在所有节点上,它会订阅所有 Pod 对象的变化,当发现一个 Pod 与 Node 绑定,也就是这个 Pod 上标记了Node的名字,而这个被绑定的 Node 就是它自己,Kubelet 就会在这个节点将 Pod 启动。
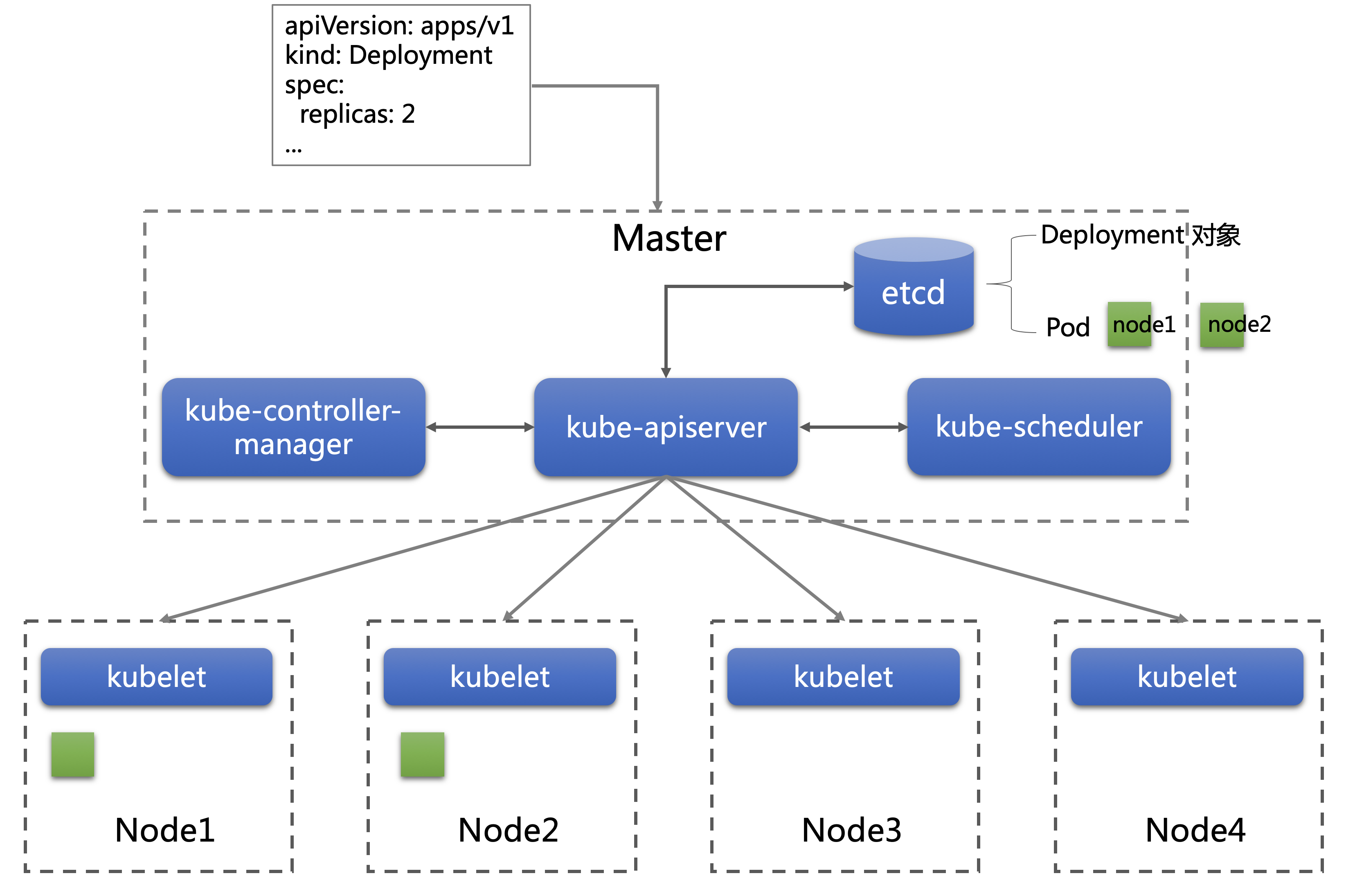
至此,用户提交的应用在Kubernetes集群中就运行起来了。
同时,上述的过程一直在循环往复。例如,用户更新了 YAML,将 replicas 改为3,并将更新后的 YAML 再次提交。kube-controller-manager会发现实际运行的 Pod 数量与用户的期望不符,它会生成一个新的 Pod 对象。紧接着 kube-scheduler 发现一个没有绑定节点的 Pod,它会按照调度算法为这个Pod寻找一个最佳节点完成绑定。最后,某个Kubelet 发现新绑定节点的 Pod 应该在本节点上运行,它会通过接口调用Docker完成 Pod 的启动。
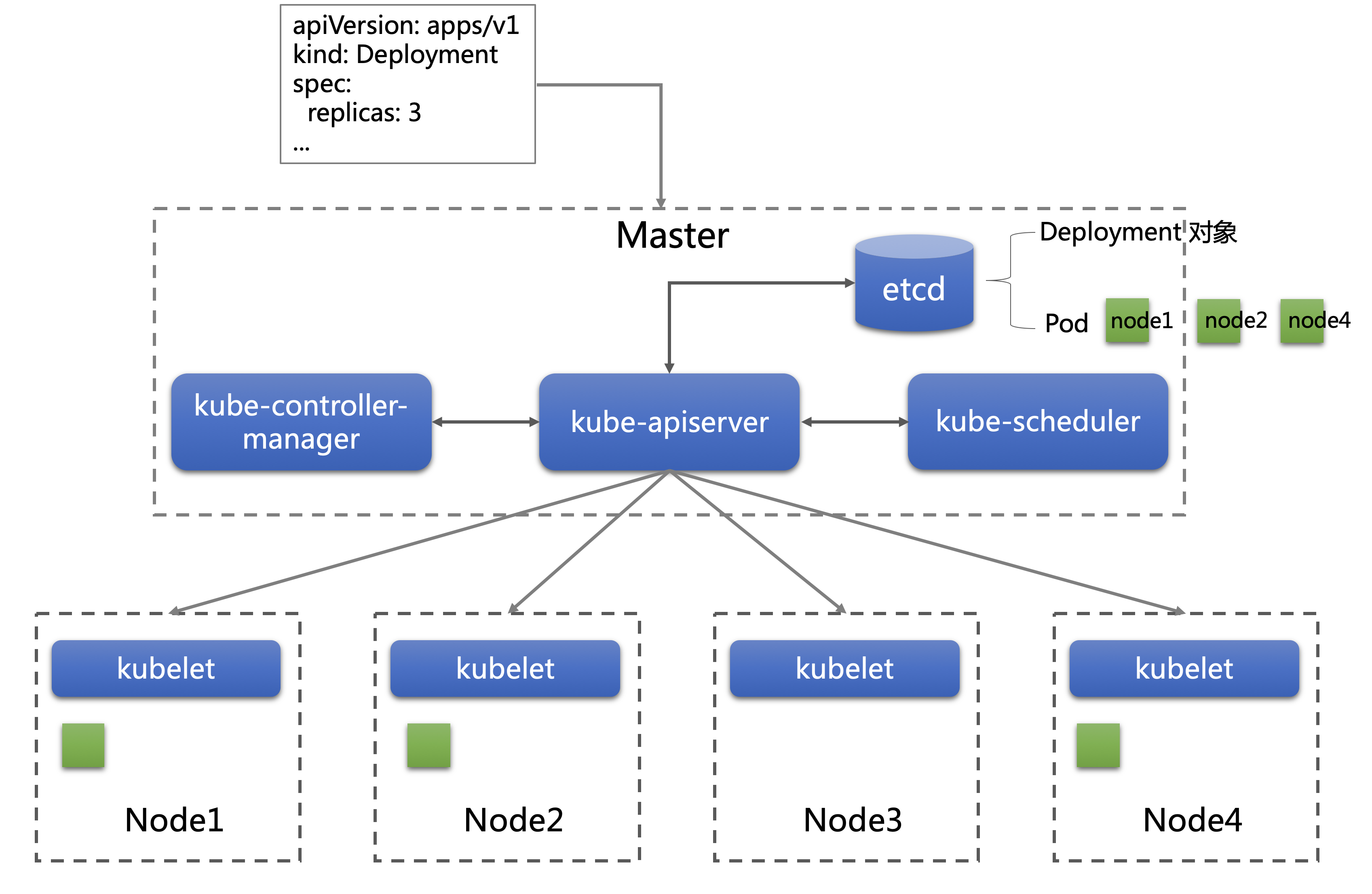
上面就是 Kubernetes 基本工作流程的简单描述,希望对你理解它的工作原理有所帮助。